About
A Data Maintenance Test consists of the execution of a series of refresh streams.
This process tracks, possibly with some delay, the state of an operational database through data maintenance functions,
The modeling of Transformation and Load (The TL in ETL) is known as Data Maintenance (DM) or Data Refresh.

Dimension Classification
The dimension tables can be classified into one of the following types:
- Static: The contents of the dimension are loaded once during database load and do not change over time. The date dimension is an example of a static dimension.
- Historical: The history of the changes made to the dimension data is maintained by creating multiple rows for a single business key value. Each row includes columns indicating the time period for which the row is valid. The fact tables are linked to the dimension values that were active at the time the fact was recorded, thus maintaining historical truth. Item is an example of a historical dimension.
- Non-Historical: The history of the changes made to the dimension data is not maintained. As dimension rows are updated, the previous values are overwritten and this information is lost. All fact data is associated with the most current value of the dimension. Customer is an example of a Non-Historical dimension
Process
The TPC-DS data maintenance process starts from generated flat files that are assumed to be the output of the external Extraction process.
Reading the refresh data is a timed part of the data maintenance process. The data set for a specific refresh run must be loaded and timed as part of the execution of the refresh run. The loading of data must be performed via generic processes inherent to the data processing system or by the loader utility the database software provides and supports for general data loading. It is explicitly prohibited to use a loader tool that has been specifically developed for TPC-DS.
Function
Data maintenance functions perform insert and delete operations that are defined in pseudo code.
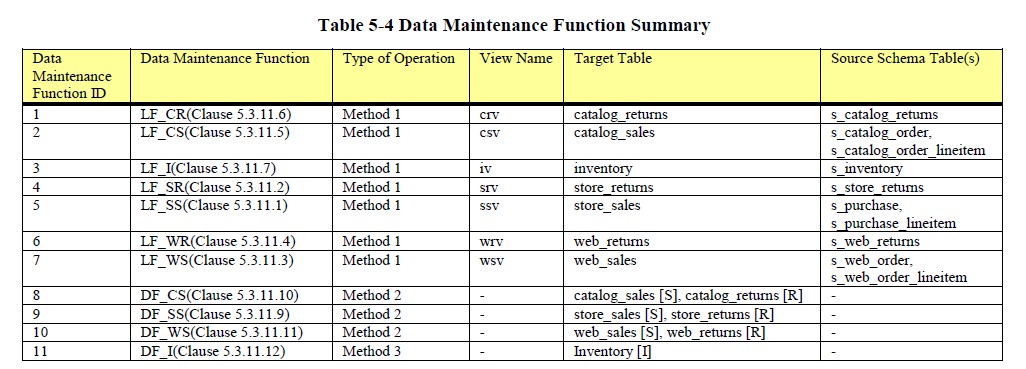
where:
- LF = insertupdate Fact with the help of a view
- DF = delete Fact
Type
Insert/Update
Each data maintenance function inserting or updating rows in dimension and fact tables is defined by the following components:
- a) Descriptor, indicating the name of the data maintenance function in the form of :
- DM_<abbreviation of data warehouse table> for dimensions.
- and LF_<abbreviation of the data warehouse fact table> for fact tables. Example: LF_CR for catalog_returns.
- b) The data maintenance method describes the pseudo-code of the data maintenance function.
- c) A SQL view V describing which tables of the source schema need to be joined to obtain the correct rows to be loaded.
- d) The column mapping defining which source schema columns map to which data warehouse columns;
Each data maintenance function contains a table with column mapping between its view V and its data warehouse table T.
View
The primary key of V is denoted in bold letters on the left side of the mapping table.
V is a logical table that does not need to be instantiated. The primary key of V is defined in the data maintenance function.
Delete
Each data maintenance function deleting rows from fact tables is defined by the following components:
- a) Descriptor, indicating the name of the data maintenance function in the form of DF_<abbreviation of data warehouse fact table>. The extension indicates the data warehouse fact table from which rows are deleted.
- b) Tables: S and R, or I in case of inventory
- c) Two dates: Date1 and Date2
- d) The data maintenance method indicates how data is deleted
Comment: In the flat files generated by dsdgen for data maintenance, there are 2 files that relate to deletes.
- One flat file (delete_<n>.dat) associated with deletes applies to sales and returns for store, web, and catalog where <n> denotes the set number, defined in Clause 5.1.2).
- The second flat file (inventory_delete_<n>.dat) applies to inventory only where <n> denotes the set number, defined in Clause 5.1.2). In each delete the flat file there are 3 sets of start and end dates for the delete function. Each of the 3 sets of dates must be applied.
DF_SS:
- S=store_sales
- R=store_returns
- Date1 as generated by dsdgen Date2 as generated by dsdgen
DF_CS:
- S=catalog_sales
- R=catalog_returns
- Date1 as generated by dsdgen Date2 as generated by dsdgen
DF_WS:
- S=web_sales
- R=web_returns
- Date1 as generated by dsdgen Date2 as generated by dsdgen
DF_I:
- I=Inventory
- Date1 as generated by dsdgen Date2 as generated by dsdgen
Method
Depending on which operation they perform and on which type of table, they are categorized as follow:
- Method 1: fact insert data maintenance
- Method 2: fact delete data maintenance
- Method 3: inventory delete data maintenance
Method 1
This function reads rows from a source view V and insert rows into a target data warehouse table T.
Fact Table Load
for every row v in view V corresponding to fact table F:
get row v into local variable lv
for every type 1 business key column bkc in v:
get row d from dimension table D corresponding to bkc
where the business keys of v and d are
equal update bkc of lv with surrogate key of d
end for
for every type 2 business key column bkc in v
get row d from dimension table D corresponding to bkc
where the business keys of v and d are equal and rec_end_date is NULL
update bkc of lv with surrogate key of d
end for
insert lv into F
end for
Method 2
Sales and Returns Fact Table Delete
Delete rows from R with corresponding rows in S where d_date between Date1 and Date2
Delete rows from S where d_date between Date1 and Date2
D_date is a column of the date_dim dimension. D_date has to be obtained by joining to the date_dim dimension on sales date surrogate key. The sales date surrogate key for the store sales is ss_sold_date_sk, for catalog it is cs_sold_date_sk and for web sales it is ws_sold_date_sk.
Method 3
Inventory Fact Table Delete
Delete rows from I where d_date between Date1 and Date2
Comment: D_date is a column of the date_dim dimension. D_date has to be obtained by joining to the date_dim dimension on inv_date_sk.
Implementation
See:
- for update: tpcds_home\tests\dm_*.sql
- for insert: tpcds_home\tests\if_*.sql
Data
Definition
The refresh data sets of each data maintenance function must be generated using dsdgen.
The output file for each table of the refresh data set can be split into n files where each file contains approximately 1/n of the total number of rows of the original output file. The order of the rows in the original output file must be preserved, such that the concatenation of all n files is identical to the original file.
The refresh data consists of a series of refresh data sets, numbered 1, 2, 3…n. <n> is identical to the number of streams used in the Throughput Tests of the benchmark. Each refresh data set consists of <N> flat files.
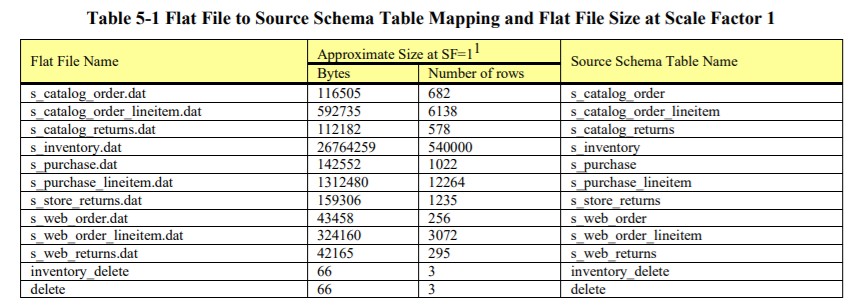
where:
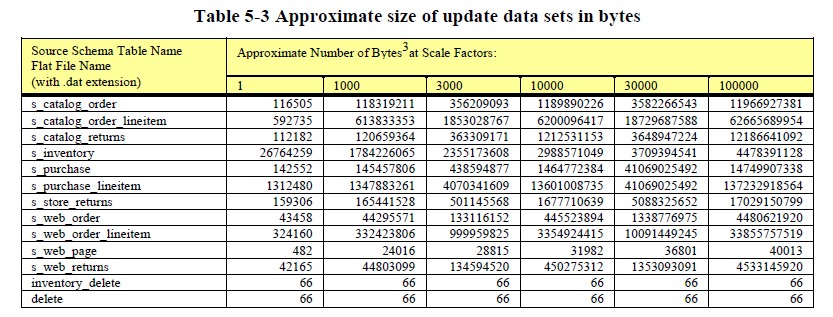
Data Generation
Example to generate the refresh data files with dsdgen in /tmp for the 3rd update stream:
# Linux
dsdgen –scale 100 –dir /tmp –update 3
# Windows
dsdgen /scale 100 /dir C:\tmp /update 3
The output files will be of the form s_<table>_<stream>.csv.
Since dsdgen only generates 200-300GB/hour (on a 2-3GHz x86 processor), it is useful to run multiple parallel streams when generating large amounts of data. Here’s an example for the 3rd stream/child of 10 parallel streams:
dsdgen –scale 100 –dir /tmp –update 3 –parallel 10 –child 3
See tpcds_home\tests\gen_update_data.sh
#!/bin/sh
# $id:$
# $log:$
cd temp_build
if [ -f FAILED ]
then
exit
fi
rm -rf /data/s_*.csv
./dbgen2 -f -dir /data -update 1 > gen_update_data.out 2>&1 || exit -1
cat - << _EOF_ > /tmp/goal
100 s_brand.csv
100 s_business_address.csv
100 s_call_center.csv
100 s_catalog.csv
100 s_catalog_order.csv
900 s_catalog_order_lineitem.csv
100 s_catalog_page.csv
100 s_catalog_promotional_item.csv
84 s_catalog_returns.csv
100 s_category.csv
100 s_class.csv
100 s_company.csv
100 s_customer.csv
100 s_division.csv
100 s_inventory.csv
100 s_item.csv
100 s_manager.csv
100 s_manufacturer.csv
100 s_market.csv
100 s_product.csv
100 s_promotion.csv
3 s_purchase.csv
15 s_purchase_lineitem.csv
100 s_reason.csv
100 s_store.csv
100 s_store_promotional_item.csv
2 s_store_returns.csv
100 s_subcategory.csv
100 s_subclass.csv
100 s_warehouse.csv
3 s_web_order.csv
27 s_web_order_lineitem.csv
100 s_web_page.csv
100 s_web_promotional_item.csv
3 s_web_returns.csv
100 s_web_site.csv
99400 s_zip_to_gmt.csv
103237 total
_EOF_
wc -l /data/*.csv > /tmp/results
diff -w /tmp/goal /tmp/results || exit -1
rm /tmp/goal /tmp/results gen_update_data.out