Spark Java - Installation and configuration on IDEA
About
How to configure IDEA against Spark with Java
Articles Related
Configuration
This section shows the important configuration that you need to pass to any Spark App in order to have a valid run.
Hadoop Home
The HADOOP_HOME environment variable is mandatory because it's used to locate the winutils utility.
If you don't have it, you got this kind of error:
java.io.IOException: (null) entry in command string: null ls -F C:\spark-2.2.0-metastore\scratchdir
In the default configuration of Java Application, add the HADOOP_HOME
Classpath
To load the config file, the location of the config file must be in the classpath. The OS shell script use the environment variable to add them but inside Idea, you need to add them manually.
Steps
Local installation
This local installation is only needed if you want to:
- use the spark OS shell to submit your application for instance.
- modify your configuration (such as the location of the warehouse and of the metastore)
Dependencies
The following dependencies must be added to your project. You may need to exclude some if you don't use a specific module (for instance, stream).
They are all marked provided as we don't want them in the jar.
Example of pom.xml file
<properties>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.8</scala.version>
<spark.project.version>2.3.1</spark.project.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.project.version}</version>
<scope>provided</scope>
</dependency>
<!-- Needed to recognize the scala language (import, ...) -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<!-- Used in scala example. scopt is a command line parser -->
<dependency>
<groupId>com.github.scopt</groupId>
<artifactId>scopt_${scala.binary.version}</artifactId>
<version>3.7.0</version>
</dependency>
</dependencies>
Idea Application
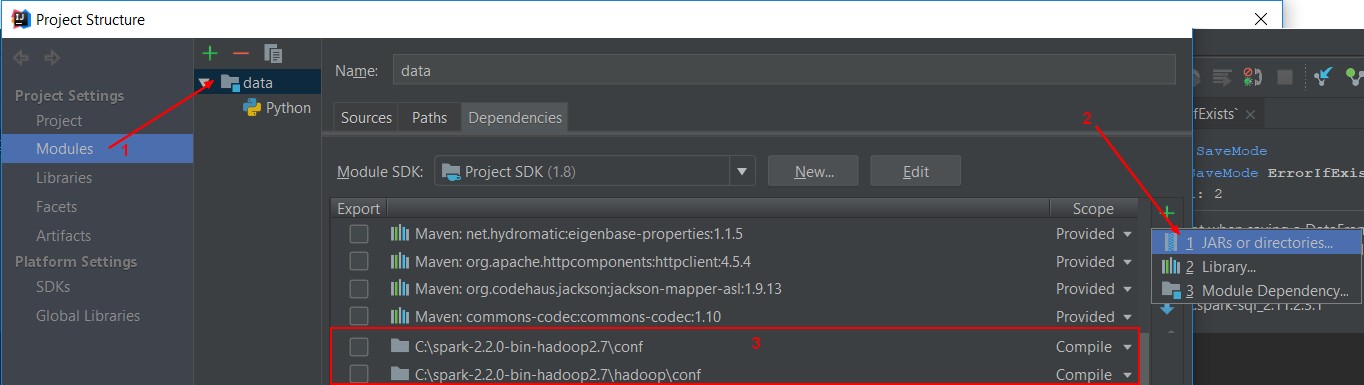
Module classpath
To add to the classpath, the conf directory, go to the project directory and add them.
Default run
Example: Edit Configuration > (1) Defaults > (2) Application
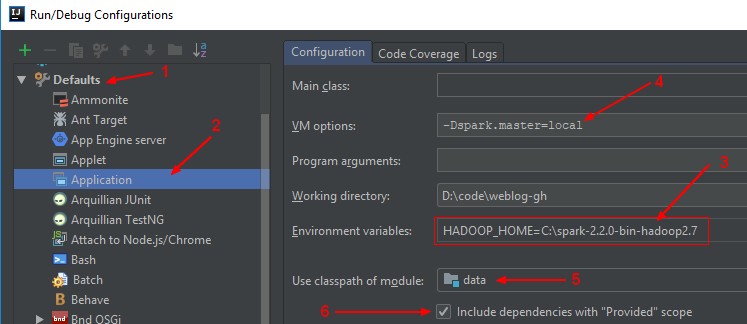
- (3) Env: Hadoop Home
- (4) Master: I define the master also in the default run.
- (5) Classpath: of the module. See module_classpath
- (6) Include: Provided
Maven Run
In Maven, when using the Surefire plugin, you need to add the conf directory file of HADOOP and SPARK in the classpath.
To achieve this, we add them in the environment of the maven runner:
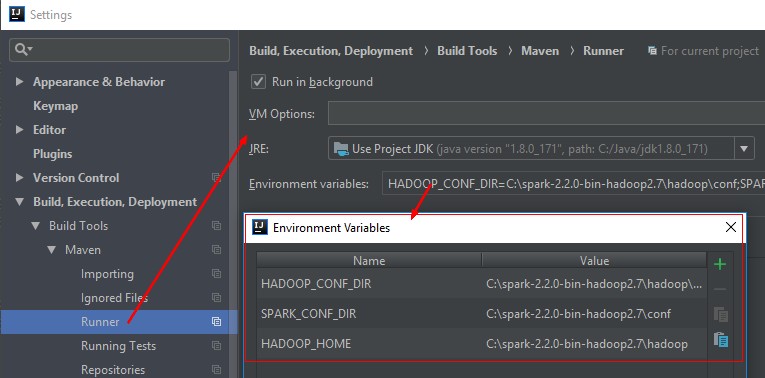
and we modify the surefire plugin to add them in the classpath:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.21.0</version>
<configuration>
<additionalClasspathElements>
<additionalClasspathElement>${env.HADOOP_CONF_DIR}</additionalClasspathElement>
<additionalClasspathElement>${env.SPARK_CONF_DIR}</additionalClasspathElement>
</additionalClasspathElements>
</configuration>
</plugin>
</plugins>