Data Mining - (Function|Model)
About
The model is the function, equation, algorithm that predicts an outcome value from one of several predictors.
During the training process, the models are build. A model uses a logic and one of several algorithm to act on a set of data.
The notion of automatic discovery refers to the execution of data mining models.
The “best” model is often found after building models of several different types, or by trying different technologies or algorithms.
The process of applying a model to new data is known as scoring (or predicting).
A Model object is the result of applying an algorithm to data.
Models can be used in several operations. They can be:
- Inspected, for example to examine the rules produced from a decision tree or association
- Tested for accuracy
- Applied to data for scoring
- Exported/Imported
Considerations:
- simplicity,
- speed,
Essentially, all models are wrong, but some are useful
As we can't model everything, we have to think about what's the best trade-off between accuracy and simplicity.
Articles Related
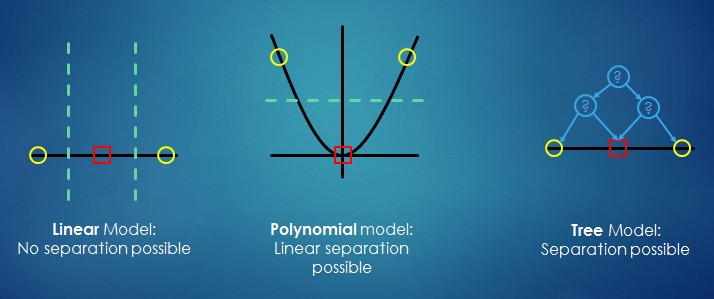
Complexity
The model (complexity|flexibility) of a model is given by:
- the model size (ie the number of regression coefficient)
- the degree level
For example:
- in a linear model, the model complexity is the number of features (or the number of coefficients) that we fit in the model. A low model complexity means a few number of features or coefficients or predictors. High means a large number.
- in a polynomial model: The model complexity increases with degree. An higher complexity is a higher order of polynomial.
More complicated models typically have lower bias at the cost of higher variance. This has an unclear effect on Reducible Error (could go up or down) and no effect on Irreducible Error.
Function
Each data mining function specifies a class of problems that can be modelled and solved. It's not a mathematical function but a categorical function.
Data mining problem can be divided into two types of “Learning”:
- and unsupervised.
Terminology:
- Supervised Learning (“Training”)
- Unsupervised Learning (sometimes: “Mining”)
Notions of supervised and unsupervised learning are derived from the science of machine learning, which has been called a sub-area of artificial intelligence.
Artificial intelligence refers to the implementation and study of systems that exhibit autonomous intelligence or behavior of their own. Machine learning deals with techniques that enable devices to learn from their own performance and modify their own functioning. Data mining applies machine learning concepts to data.
| Function | (Un)Supervised | (Predic|Descrip)tive | Description |
|---|---|---|---|
| Attribute Importance | Supervised | Predictive | Identifies the attributes that are most important in predicting a target attribute |
| Classification | Supervised | Predictive | Assigns items to discrete classes and predicts the class to which an item belongs |
| Regression | Supervised | Predictive | Approximates and forecasts continuous values |
| Anomaly Detection | Unsupervised | Descriptive | Identifies items (outliers) that do not satisfy the characteristics of “normal” data |
| Association Rules | Unsupervised | Descriptive | Finds items that tend to co-occur in the data and specifies the rules that govern their co-occurrence |
| Clustering | Unsupervised | Descriptive | Finds natural groupings in the data |
| Feature Extraction | Unsupervised | Descriptive | Creates new attributes (features) using linear combinations of the original attribute |
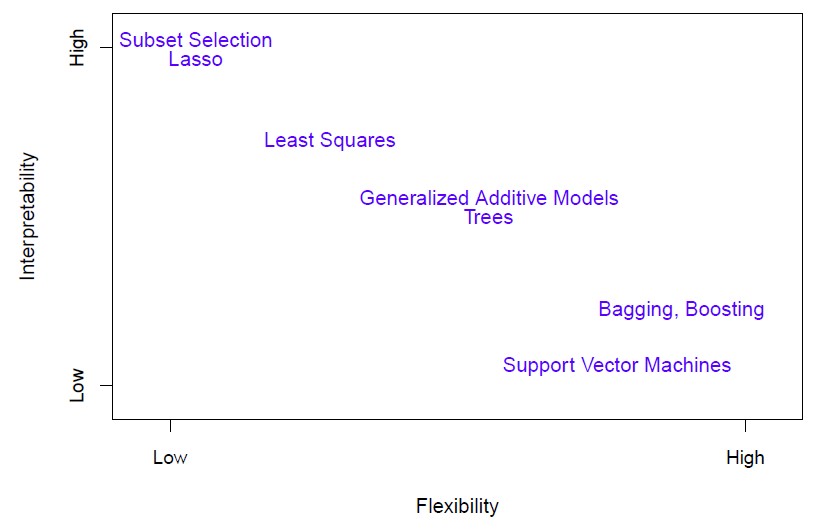
Trade-off
- Prediction accuracy versus interpretability. Easy interpretation
- Good fit versus overfi�t or under-fit�ting.
- Parsimony versus black-box. A simpler model involving fewer variables is preferable over a black-box predictor involving them all.
Property
Model Signature
The model signature is the set of data attributes used to build a model. Some or all of the attributes in the signature should be present for scoring.
If some columns are not present, they are disregarded. If columns with the same names but different data types are present, the model attempts to convert the data type.
The model signature does not necessarily include all the columns in the build data. Algorithm-specific criteria may cause the model to ignore certain columns. Other columns may be eliminated by transformations. Only the data attributes actually used to build the model are included in the signature.
The target and case ID columns are not included in the signature.
Sparse
Models which only involves a subset of the variables.
The lasso shrinkage method produces sparse model because it will shrink (set) the variables regression coefficient to zero.
Dense
Models which involves all variables.
True
The True model is the model that represents perfectly the response without noise.
Type
Supermodels
Mining models are known as supermodels, because they contain the instructions for their own Data Preparation.
Data transformation are automatic and embedded in the data mining model.
In Automatic Data Preparation (ADP) mode, the model itself transforms the build data according to the requirements of the algorithm. The transformation instructions are embedded in the model and reused whenever the model is applied.
You can choose to add your own transformations to those performed automatically by Oracle Data Mining. These are embedded along with the automatic transformation instructions and reused with them whenever the model is applied. In this case, you only have to specify your transformations once — for the build data. The model itself will transform the data appropriately when it is applied.
Documentation / Reference
- See : Oracle Data Mining Application Developer's Guide for a discussion of scoring and deployment in Oracle Data Mining.