Map Reduce (MR) Framework
About
Map reduce is a distributed execution What is a framework ?.
The MapReduce programming model (and a corresponding system) was proposed in a 2004 paper from a team at Google as a simpler abstraction for processing very large datasets in parallel.
- Free variant: hadoop
Map-reduce is a high-level programming model and implementation for large-scale parallel data processing.
Parallel processing pattern
Map reduce is a lead up of parallel processing.
All distributed algorithm can be expressed with this two times items.
The Map and Reduce functions are executed serially. All operations in the Map phase complete before the operations in the Reduce phase start.
Each machine can execute 100 map tasks, which gives a decent amount of parallelism without wasting resources.
When implementing Map reduce, parallel happen for free.
MapReduce is a lightweight framework, providing:
- Automatic parallelization and distribution
- I/O scheduling
- Status and monitoring
Map reduce is deployed for really really large clusters more than 10
Because there was no open-source parallel database at the time, the open-source implementation of Map Reduce was a good alternative to expensive parallel database implementations. Map Reduce became extremely popular even though parallel databases did exist when it was first introduced.

Data Model
Files !
A file = a bag of (key, value) pairs
A map-reduce program:
- Input: a bag Of (input_key, value) pairs
- Output: a bag of (output_key, value) pairs
A machine must be able to process the key-value pairs in main memory for the Map Reduce framework to function effectively.
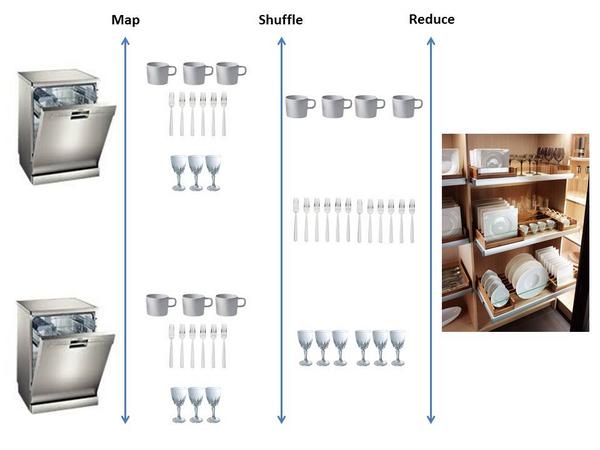
Cons/Pros
Pros
Designed to:
- leverage parallelism
- scale on thousand of commodity computer
- leverage Fault-tolerance to prevent unreliable hardware
And can then:
- process large files
- provide maximize throughput of large scans
- provide an inexpensive processing capacity
Framework:
- Flexible development platform
- Solution Ecosystem
- Load data first, structure later
Pattern
There’s a pattern ….
- A function that maps a read to a trimmed read
- A function that maps a TIFF image to a PNG image
- A function that maps a set of parameters to a simulation result
- A function that maps a document to its most common word
- A function that maps a document to a histogram of word frequencies
Cluster Computing
- Large number of commodity servers, connected by high speed, commodity network
- Rack: holds a small number of sen/ers
- Data center: holds many racks
Massive parallelism:
- 100s, or 1000s, or 10000s servers
- Many hours
Failure:
- If mean-time-between-failure is 1 year
- Then 10000 servers have one failure / hour
Distributed File System (DFS)
- For very large files: TBs, PBs
- Each file is partitioned into chunks, typically 64MB
- Each chunk is replicated several times (>=3), on different racks, for fault tolerance
Implementations:
- GoogIe’s DFS: GFS, proprietary
- Hadoop’s DFS: HDFS, open source
Phase

Fault-tolerance
The Map Reduce framework provide fault tolerance during job execution.
For Map tasks, data is read from the file system (HDFS) as input and output to local storage. Reduce tasks read from local storage as input and output to the file system (HDFS). If a Reduce task fails, another Reduce task can still read the result of a Map task from local storage. If a Map task fails, it can still read input from the file system. If the system crashes after the Reduce task has finish, the data is already written to the file system. So there are multiple layers of data that we can fall back to in order to recover.
Data is stored after each phase of the Map Reduce framework, saving the output of Map tasks so if a Reduce task fails, it is not necessary to restart the Map task as well.
Task
The individual tasks in a Map Reduce job:
- are idempotent.
- and have no side effects.
They can be restarted without changing the final result. Software Design - Recovery (Restartable)
These two properties mean that given the same input, re-executing a task will always produce the same result and will not change other state. So, the results and end condition of the system are the same, whether a task is executed once or a thousand times.
Example
Compute the word frequency across 5M Documents
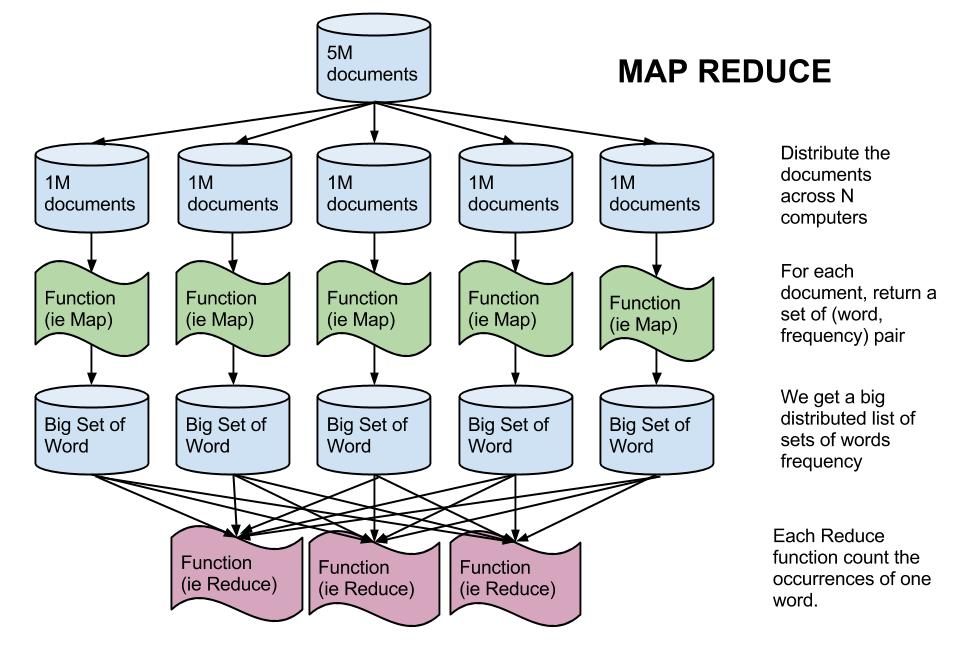
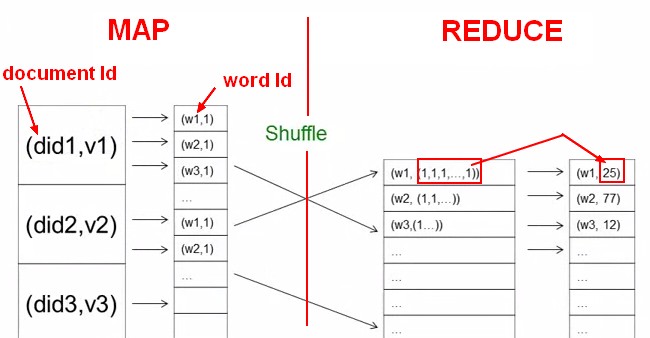
The Map task categorizes and counts words for some fraction of a document or documents and passes these counts to the Reduce tasks. Each reduce task is given on count of a word and combines the count that are passed by the Map tasks.
Build an Inverted Index
Simple Social Network Analysis: Count Friends
Simple social network dataset consisting of key-value pairs where each key is a person and each value is a friend of that person.
Algorithm Steps to count he number of friends each person has:
- Input: Person A is friend with person B
Person A, Person B
Nico, Madelief
Madelief, Nico
Rixt, Nico
Nico, Rixt
Melissa, Rixt
Rixt, Melissa
Nico, Melissa
Melissa, Nico
- Map Step: Pair with the person and the number of friend
Nico, 1
Madelief, 1
Rixt, 1
Nico, 1
Melissa, 1
Rixt, 1
Nico, 1
Melissa, 1
- Shuffle step: All the value are grouped together
Nico, (1, 1, 1)
Madelief, (1)
Rixt, (1, 1)
Melissa, (1, 1)
- Reduce Step: The calculation
Nico, 3
Madelief, 1
Rixt, 2
Melissa, 2
Relational Join: The order schema
The Map phase produces key-value pairs that have a key that is being joined on, then distributes the tuples to the Reducers where each Reducer is given only tuples with the same key. Because each Reducer has a only tuples with the same key that we are joining on, a cartesian product will produce the correct answer for the join.
In the parallel Relational Join the Reduce task is a cartesian product because each Reduce tasks holds all tuples from both relations that have the same key. Thus, every tuple from one relation can be joined to every tuple in the other relation on each Reduce task.
Key Idea: Lump all the tuples together into one data set.
Steps:
- Input:
Order (OrderId, Account, Date)
1, Account1, d1
2, Account2, d2
3, Account3, d3
LineItem (OrderId, Product, Quantity)
1, 10, 1
1, 20, 3
2, 10, 5
2, 30, 10
3, 20, 2
- Map Step: The key value pair is tagged with the relation name (ie Order or line)
Order
1, Account1, d1 -> 1 : ("Order", 1, Account1, d1)
2, Account2, d2 -> 2 : ("Order", 2, Account2, d2)
3, Account3, d3 -> 3 : ("Order", 3, Account3, d3)
LineItem
1, 10, 1 -> 1 : ("Line", 1, 10, 1)
1, 20, 3 -> 1 : ("Line", 1, 20, 3)
2, 10, 5 -> 2 : ("Line", 2, 10, 5)
2, 30, 10 -> 2 : ("Line", 2, 30, 10)
3, 20, 2 -> 3 : ("Line", 3, 20, 2)
- Shuffle step: All the value are grouped together
1, (("Order", 1, Account1, d1), ("Line", 1, 10, 1), ("Line", 1, 20, 3))
2, (("Order", 2, Account2, d2), ("Line", 2, 10, 5), ("Line", 2, 30, 10))
3, (("Order", 3, Account3, d3), ("Line", 3, 20, 2))
- Reduce Step: The join
For Key 1:
1, Account1, d1, 1, 10, 1
1, Account1, d1, 1, 20, 3
For key 2:
2, Account2, d2, 2, 10, 5
2, Account2, d2, 2, 30, 10
For key 3:
3, Account3, d3, 3, 20, 2
Matrix Multiplication
In map reduce, you can attach value to multiples key. Ie the value A[1,1] can be (send|emit) two times to calculate the output C[1,1] and C[1,2].
- Matrix multiplication Input:
C = A x B
A has dimensions L, M
B has dimensions M, N
C will then have the dimension L, N
- Map
For each element (i,j) of A, emit
Key = (i, k), value = A[i,j]
where k in 1…N
For each element (j,k) of B, emit
Key = (j, k), value = B[j,k]
where k in 1…L
- Reduce: One reducer per output cell. In the reduce phase, emit:
- Key = (i,k)
- Value = Sum_j ( A[i,j] * B[j,k] )
Pseudo Code
Steps:
- Map function example
// input_key: document name
// input_value: document contents
map(String input_key, String input_value):
for each word w in input_value:
Emitlntermediate(w, n);
// Example of output
// ("history", 5)
// ("history", 3)
// ("history", 1)
- Combiner
// intermediate_key: word. Example "history"
// intermediate_values: . Example: 1, 1, 1, ...
combine(String intermediate_key, Iterator intermediate_values)
returns (intermediate_key, intermediate_value)
The combiner function can be the same than the reduce function. The function must be associative and commutative.
- Reduce function example
// intermediate_key: word. Example "history"
// intermediate_values: . Example: 5, 3, 1, ...
reduce(String intermediate_key, Iterator intermediate_values)
int result = O;
for each v in intermediate_values:
result += v;
EmitFinal(intermediate_key, result);
By reducing the number of key-value pairs output by the Map function, the number of key-value pairs that are passed to the Reduce machines is also reduced. Since machine doing the Map task and machines doing the Reduce task are usually connected over a network, this also reduces the amount of data transfer between machines.
Join
Three Special Join Algorithms
- Replicated: One table is very small, one is big
Broadcast join and Replicated join are the same thing. They copy the small table to all node. The map tasks can perform the join locally and the output can just be merged for the result.
- Skewed: When one join key is associated with most of the data
- Merge: If the two datasets are already grouped/sorted on the correct attribute, the join can be computed in the Map phase
Skewed / Stragglers
This is the big performance problem of map/reduce job.

One response to this problem is to split the map task in several other map/reduce tasks.
MapReduce Extensions and Contemporaries
- Pig Relational Algebra over Hadoop
- HIVE (Facebook, available open source) - SQL over Hadoop
- Impala Cloudera - SQL over HDFS; uses some HIVE code
- Cascading - Relational Algebra
- Crunch. Apache Hive and Apache Pig were built to make MapReduce accessible to data analysts with limited experience in Java programming. Crunch was designed for developers who understand Java and want to use MapReduce effectively in order to write fast, reliable applications
Map Reduce Vs RDBMS
- Databases Key ideas: Relational algebra, physical/logical data, independence
- MapReduce Key ideas: Fault tolerance, no loading, direct programming on “in situ” data
Examples of Map Reduce implementations implement declarative languages, schemas, indexing, and algebraic optimization, all of which are features of Relational Database Management Systems.
| Notion | Map Reduce Implementation |
|---|---|
| RDBMS | |
| Declarative query languages | Pig, Hive |
| Schemas (Constraint) | HIVE, Pig, DryadLINQ, Hadapt |
| Logical Data Independence (Notion of Views) | |
| Indexing | Hbase |
| Algebraic Optimization (Query Optimizer) | |
| Caching/Materialized Views | |
| ACID/Transactions (Notion of Recovery) | |
| MapReduce | |
| High Scalability | |
| Fault-tolerance | |
| One-person deployment | |
History

- 1956-1979: Stanford, MIT, CMU, and other universities develop set/list operations in LISP, Prolog, and other languages for parallel processing (see http://www-formal.stanford.edu/jmc/history/lisp/lisp.html).
- Circa 2004: Google: MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat
- Circa 2006: Apache Hadoop, originating from the Yahoo!’s Nutch Project Doug Cutting
- Circa 2008: Yahoo! web scale search indexing - Hadoop Summit, Hadoop User Group
- Circa 2009: Cloud computing with Amazon Web Services Elastic MapReduce (AWS EMR), a Hadoop version modified for Amazon Elastic Cloud Computing (EC2) and Amazon Simple Storage System (S3), including support for Apache Hive and Pig.