Apache - Pig
About
Pig is:
- An Apache open source project (From Yahoo, available open source)
- An engine for executing programs on top of Hadoop
Pig provides:
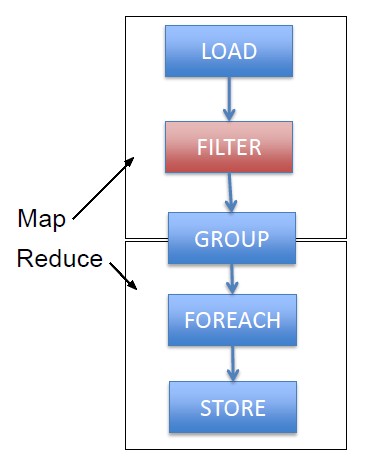
- Relational Algebra over Hadoop through its language, Pig Latin to create its own query execution plan
Not a pure relational data model. “Schema-on-Read” rather than “Schema-on-write”
Improvements on the Pig language have made it often just as efficient as writing the code in Map Reduce.
You can work with (native|in situ) data.
Pipeline are performed on collections of Tuples
Articles Related
Example
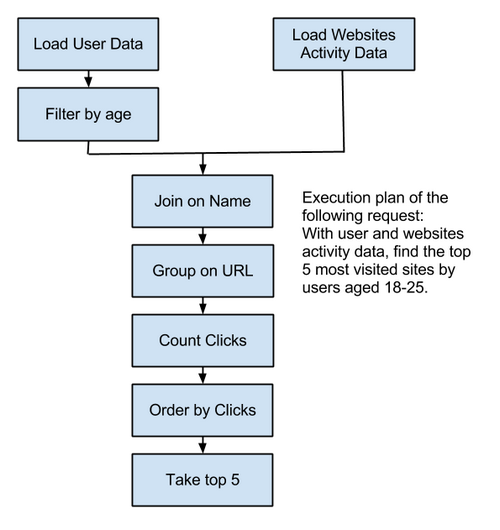
In Pig Latin
Users = load ‘users’ as (name, age);
Fltrd = filter Users by age >= 18 and age <= 25;
Pages = load ‘Activity Data’ as (user, url);
Jnd = join Fltrd by name, Pages by user;
Grpd = group Jnd by url;
Smmd = foreach Grpd generate group, COUNT(Jnd) as clicks;
Srtd = order Smmd by clicks desc;
Top5 = limit Srtd 5;
store Top5 into 'top5sites’;
Data Model
- Atom: Integer, string, etc.
- Tuple:
- Sequence of fields
- Each field of any type
- Bag:
- A collection of tuples
- Not necessarily the same type
- Duplicates allowed
- Map:
- String dictionary (key:value) (mapped to any type)
Command
No work is done until STORE is called because of lazy evaluation.
Reduce the plan to a minimum of Map Reduce jobs because they are expensive.