Data Mining - Pruning (a decision tree, decision rules)
About
Pruning is a general technique to guard against overfitting and it can be applied to structures other than trees like decision rules.
Articles Related
Decision tree
A decision tree is pruned to get (perhaps) a tree that generalize better to independent test data. (We may get a decision tree that might perform worse on the training data but generalization is the goal).
See Information gain and Overfitting for an example.
Sometimes simplifying a decision tree gives better results.
How to prune:
- Don’t continue splitting if the nodes get very small: minimum_number_cases_that_reach_a_leaf
- Build full tree and then work back from the leaves, applying a statistical test at each stage (Weka: confidenceFactor)
- Sometimes it’s good to prune an interior node, raising the subtree beneath it up one level (subtreeRaising, default true)
- Univariate vs. multivariate decision trees (Single vs. compound tests at the nodes)
Minimum number cases that reach a leaf
One simple way of pruning a decision tree is to impose a minimum on the number of training examples that reach a leaf.
Weka: This is done by J48's minNumObj parameter (default value 2) with the unpruned switch set to True. (The terminology is a little confusing. If unpruned is deselected, J48's uses other pruning mechanisms)
With the breast cancer data set:
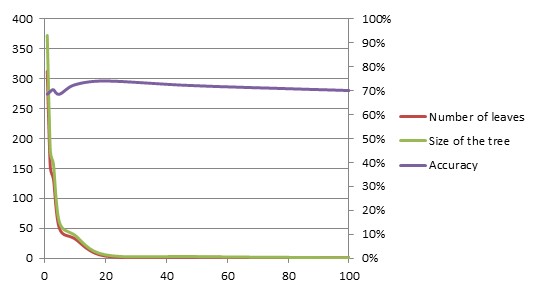
| min Num Obj | Number of leaves | Size of the tree | Accuracy |
|---|---|---|---|
| 1 | 312 | 372 | 68.5 |
| 2 | 152 | 179 | 69.6 |
| 3 | 133 | 158 | 70.3 |
| 5 | 50 | 60 | 68.5 |
| 10 | 33 | 39 | 72.4 |
| 20 | 4 | 6 | 74 |
| 50 | 2 | 3 | 72 |
| 100 | 1 | 1 | 70 |
The number of leaves in the tree decreases very rapidly as the size of each leaf is allowed to grow. The tree size follows the same trajectory as the number of leaves: it decreases very rapidly as the leaf size grows.
Confidence Factor
| confidence Factor J48 | Accuracy |
|---|---|
| 0.005 | 73.0769 |
| 0.05 | 75.5245 |
| 0.1 | 75.5245 |
| 0.25 | 75.5245 |
| 0.5 | 73.4266 |