
Data Mining - (Parameters | Model) (Accuracy | Precision | Fit | Performance) Metrics
About
Accuracy is a evaluation metrics on how a model perform.
Normal Accuracy metrics are not appropriate for evaluating methods for rare event detection
Articles Related

Problem type
Regression
Parameters
- Hypothesis testing: t-statistic and p-value. The p value and t statistic measure how strong is the evidence that there is a non-zero association. Even a weak effect can be extremely significant given enough data.
Model
How about the overall fit of the model, the accuracy of the model?
<math>R</math> is the correlation between predicted and observed scores whereas <math>R^2</math> is the percentage of variance in Y explained by the regression model.
Error
List of several error calculations:
- The squared error. The squared error is the sum of the squared difference between the actual value and the predicted value.
<MATH> \text{Squared error}= \sum_{i=1}^{n} \left (x^i - \sum_{j=0}^{k}{w_j}.{a_j^i} \right)^2 </MATH>
- Mean Absolute Error:
<MATH> \text{Mean Absolute Error}= \frac{|p_1-a_1|+\dots+|p_n-a_n|}{n} </MATH>
- Relative absolute error:
<MATH> \text{Relative absolute error}= \frac{|p_1-a_1|+\dots+|p_n-a_n|}{|a_1-\bar{a}|+\dots+|a_n-\bar{a}|} </MATH>
- Root relative squared error:
<MATH> \text{Root relative squared error}= \sqrt{\frac{(p_1-a_1)^2+\dots+(p_n-a_n)^2}{(a_1-\bar{a})^2+\dots+(a_n-\bar{a})^2}} </MATH>
Classification
The accuracy metrics are calculated with the help of a Machine Learning - Confusion Matrix
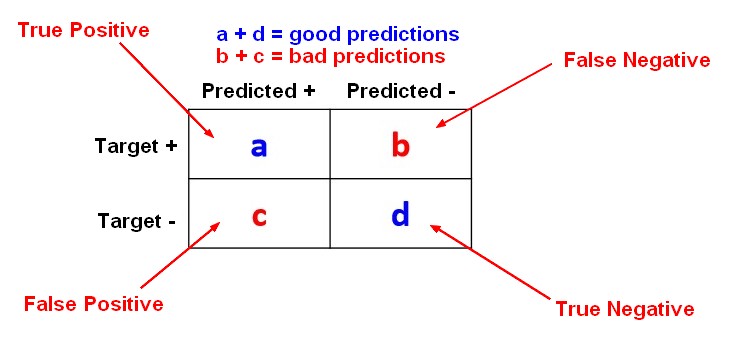
Accuracy
<MATH> \begin{array}{rrc} Accuracy & = & \frac{\text{Number of correct predictions}}{\text{Total of all cases to be predicted}} \\ & = & \frac{a + d}{a + b + c + d} \end{array} </MATH>
Accuracy is not really a reliable metric for the real performance of a classifier when the number of samples in different classes vary greatly (unbalanced target) because it will yield misleading results.
For example, if there were 95 cats and only 5 dogs in the data set, the classifier could easily be biased into classifying all the samples as cats. The overall accuracy would be 95%, but in practice the classifier would have a 100% recognition rate for the cat class but a 0% recognition rate for the dog class
The (error|misclassification) rates are good complementary metrics to overcome this problem.
Null Rate
The accuracy of the baseline classifier.
The baseline accuracy must be always checked before choosing a sophisticated classifier. (Simplicity first)
Accuracy isn’t enough. 90% accuracy need to be interpreted against a baseline accuracy.
A baseline accuracy is the accuracy of a simple classifier.
If the baseline accuracy is better than all algorithms accuracy, the attributes are not really informative.
Error rate
Statistics Learning - (Error|misclassification) Rate - false (positives|negatives)
Glossary
True
The true accuracy is the accuracy calculated on the entire data set (no data set split)