
About
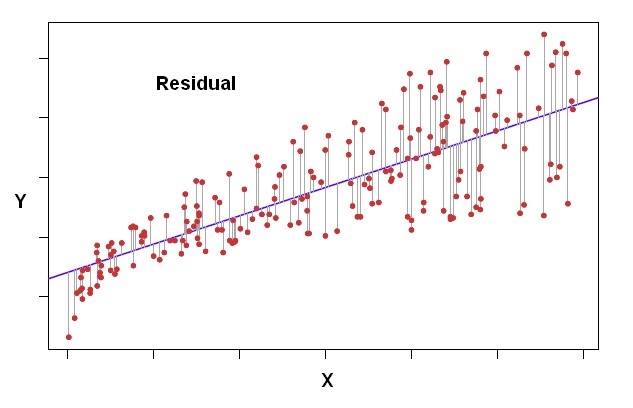
The residual is a deviation score measure of prediction error in case of regression.
The difference between an observed target and a predicted target in a regression analysis is known as the residual and is a measure of model accuracy.
The error term is an unobserved variable as:
- it's unsystematic (whereas the bias is)
- we can't see it
- we don't know what it is
In a scatterplot the vertical distance between a dot and the regression line reflects the amount of prediction error (known as the “residual”).
Articles Related
Equation
Standard
<math>e = Y - \hat{Y}</math>
where in a regression
- <math>e</math> is the error (residual)
- <math>Y</math> is the target raw score
- <math>\hat{Y}</math> is the target predicted score
Variance and bias
The ingredients of prediction error are actually:
- bias: the bias is how far off on the average the model is from the truth.
- and variance. The variance is how much that the estimate varies around its average.
Bias and variance together gives us prediction error.
This difference can be expressed in term of variance and bias:
<math>e^2 = var(model) + var(chance) + bias</math>
where:
- <math>var(model)</math> is the variance due to the training data set selected. (Reducible)
- <math>var(chance)</math> is the variance due to chance (Not reducible)
- bias is the average of all <math>\hat{Y}</math> over all training data set minus the true Y (Reducible)
As the flexibility (order in complexity) of f increases, its variance increases, and its bias decreases. So choosing the flexibility based on average test error amounts to a bias-variance trade-o ff.
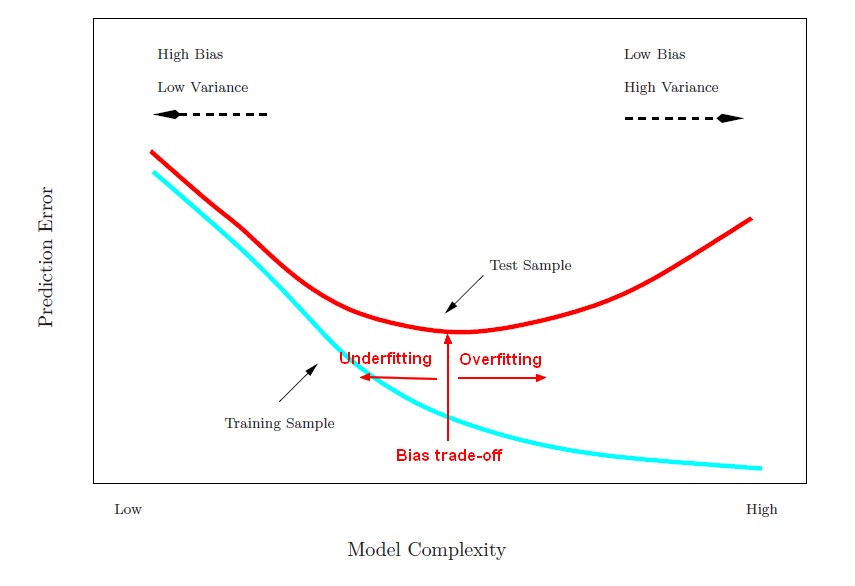
See Statistics - Bias-variance trade-off (between overfitting and underfitting)