
Data Mining - (Boosting|Gradient Boosting|Boosting trees)
About
Boosting forces new classifiers to focus on the errors produced by earlier ones. boosting works by aggressively reducing the training error
Gradient Boosting is an algorithm based on an ensemble of decision tree similar to random forests.
Instead of creating trees from different random subsets, Boosting trees take the error from the previous tree and use it to improve the next one.
It's an iterative algorithm. The idea is that you create a model, and then take a look at the instance that are misclassified (The hard one to classify). You put extra weight on those instance to make a training set for producing the next model in the iteration. This encourage the new model to become an “expert” for instance that were misclassified.
Iterative: new models are influenced by performance of previously built ones
- extra weight for instances that are misclassified (“hard” ones)
- encourage new model to become an “expert” for instances misclassified by earlier models
- Intuitive justification: committee members should complement each other’s expertise
- Uses voting (or, for regression, averaging) but weights models according to their performance
If there is no structure to the features or if you have a limited amount of time to spend on a problem, one should definitely consider boosted trees.
Boosting is sequential (not parallel).
Articles Related
Property
Boosting seems to not overfit (Why boosting does'nt overfit)
Boosting
DecisionStump
In weka: meta > AdaBoostM1. It's a standard and very good implementation. AdaBoostM1 utilizes by default DecisionStump as its base learner
Baseline
Boosting the baseline algorithm (No Rule) will produce the same classifier for practically any subset of the data. Combining these identical classifiers would give the same result as the baseline by itself.
Performance
The default configuration of AdaBoostM1 is 10 boosting iterations using the DecisionStump classifier.
Performance might improve if :
- 100 iterations were used instead. See below.
- you kept to 10 iterations but used J48 instead of DecisionStump.
Number of iterations
With boosting, the accuracy generally improves, up to an asymptote, as the number of iterations increases.
Example with AdaBoostM1 on the diabetes dataset.
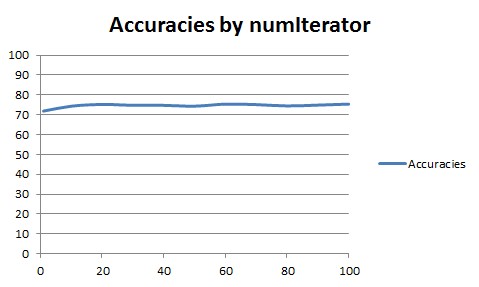
| numIterations | Accuracies |
|---|---|
| 1 | 71.875 |
| 10 | 74.349 |
| 20 | 75.2604 |
| 30 | 74.7396 |
| 40 | 74.7396 |
| 50 | 74.349 |
| 60 | 75.3906 |
| 70 | 75.1302 |
| 80 | 74.4792 |
| 90 | 74.8698 |
| 100 | 75.3906 |