About
Shrinkage methods are more modern techniques in which we don't actually select variables explicitly but rather we fit a model containing all p predictors using a technique that constrains or regularizes the coefficient estimates, or equivalently, that shrinks the coefficient estimates towards zero relative to the least squares estimates.
These methods do not use full least squares to fit but rather different criterion that has a penalty that:
- penalize the model for having a big number of coefficients or a big size of coefficients
- will shrink the coefficients towards, typically, 0.
This shrinkage (also known as regularization) has the effect of reducing variance and can also perform variable selection.
These methods are very powerful. In particular, they can be applied to very large data where the number of variables might be in the thousands or even millions.
L1, L2 regularization ?
Articles Related
Methods
Ridge regression vs Lasso
In science and therefore in statistics, there is no rule that means that you should always use one technique over another. It depends on the situation.
The lasso encourages sparse model, whereas with ridge we get a dense model. Then if the true model is quite dense, we could expect to do better with ridge. If the true model is quite sparse, we could expect to do better with the lasso.
Because we don't know the true model, it's typical to apply both methods and use cross-validation to determine the best model.
Prediction Error
Ridge performs better than Lasso
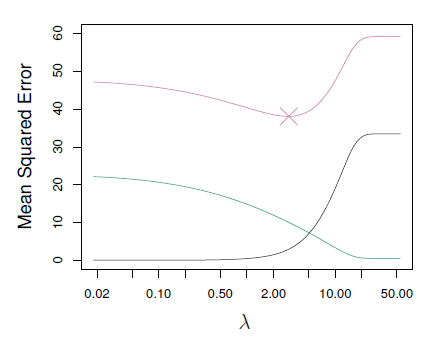
This picture, for the Lasso, is a plots of :
- squared bias (black),
- variance (green),
- and test error MSE (purple)
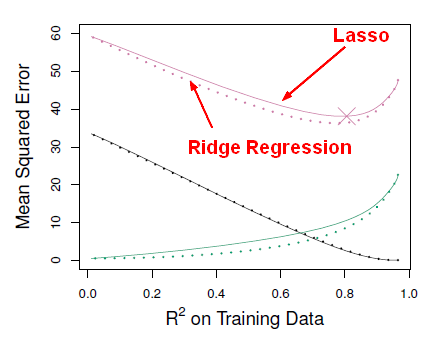
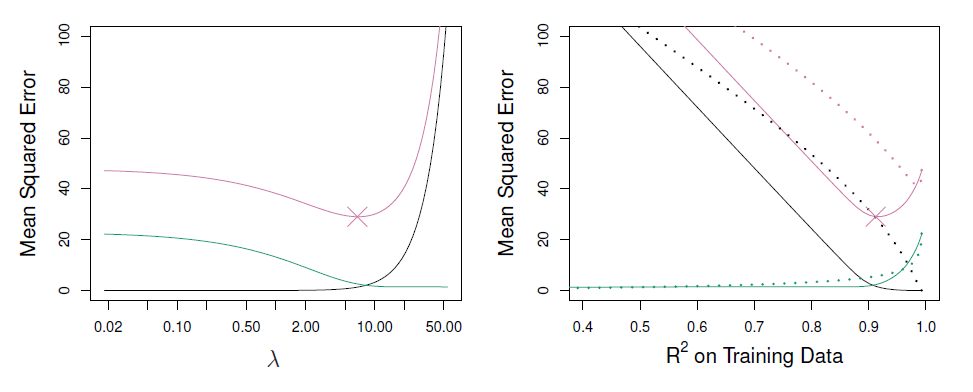
This picture is a comparison of:
- squared bias (black),
- variance (green)
- and test error MSE (purple)
between lasso (solid) and ridge (dashed). Both are plotted against their R2 on the training data, as a common form of indexing. The crosses in both plots indicate the lasso model for which the MSE is smallest.
The method are very similar. Ridge is a little better. Lasso don't do better at all because the true model is not sparse. The true model actually involves 45 variables, all of which of the given non-zero coefficients in the population. It's not surprising than Lasso don't do better than ridge in most of the case.
The x-axis is the r-squared on the training data and not lambda because we're plotting both ridge regression and the Lasso and that lambda means two different things for those two models. r-squared on the training data is a kind of a universally sensible thing to measure, regardless of what the type of model is.
Lasso performs better than Ridge
Penalty
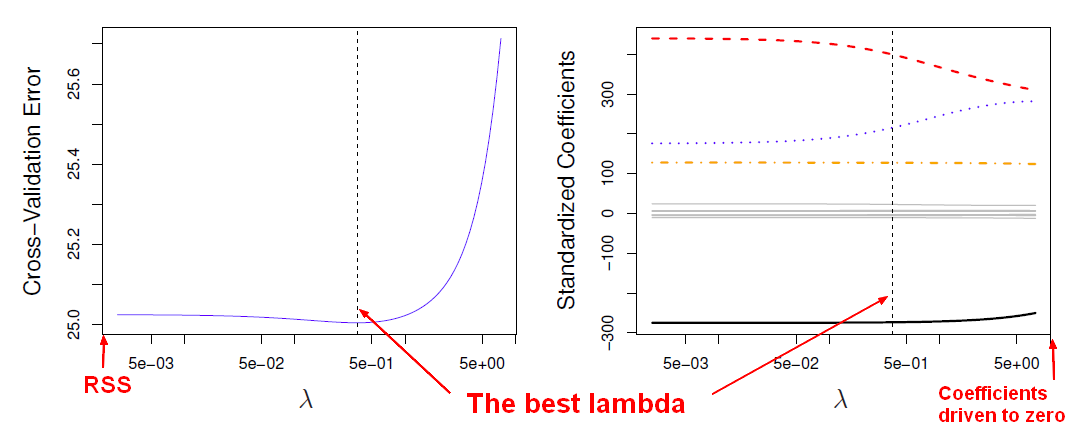
When the penalty term is zero, we get a full least square and when lambda is infinity, we get no solution. So choosing the penalty term is really important.
We have to use cross-validation because the d is unknown (number of parameter: degree of freedom?)
Model Selection
for selecting the tuning parameter (ie the penalty) for Ridge Regression and Lasso, it's really important to use a method that doesn't require the value of the model size (D), because it's hard to know what D is. So cross-validation fits the bill perfectly.
- We divide the data up into K parts. We'll say K equals 10.
- We fit the model on nine parts (with Ridge Regression of Lasso) for a whole range of lambdas, for the nine parts.
- We record the error on the 10th part.
- We do that in turn for all 10 parts, playing the role of the validation set.
- And then we add up all the errors together, and we get a cross-validation curve as a function of lambda.