Statistics - Bayes’ Theorem (Probability)
About

Bayesian probability is one of the different interpretations of the concept of probability and belongs to the category of evidential probabilities.
In the Bayesian view, a probability is assigned to a hypothesis, whereas under the frequentist view, a hypothesis is typically tested without being assigned a probability.
The Bayes theorem defines the probability of the event B and the event A (the evidence or the priori) happening (<math>P(A \cap B)</math> ) with the following formula:
<MATH> P(A \text{ and } B) = P(A) . P(B \text{ after } A) = P(B) . P(A \text{ after } B) \\ P(A \cap B) = P(A|B) . P(B) = P(B|A) . P(A) </MATH>
where:
- <math>P(A \cap B) = P(A \text{ and } B)</math> is the probability of A and B happening.
- <math>P(A | B) = P(A \text{ after } B)</math> is the probability of event A happening given that event B has already happened
- <math>P(B | A) = P(B \text{ after } A) </math> is the probability of event B happening given that event A has already happened
- <math>P(A)</math> is the probability of A happening across the board
- <math>P(B)</math> is the probability of B happening across the board
Articles Related
Prior
To evaluate the probability of a hypothesis <math>P(A \cap B)</math> , the Bayesian probabilist specifies some prior probability (<math>P(A)</math> of <math>P(B)</math> ).
This prior probability is also known as marginal depending on the probability direction (ie <math>P(A|B)</math> of <math>P(B|A)</math> )
One of its benefit is also its weakness: You have the ability to incorporate prior knowledge but you also need to incorporate prior knowledge.
Different people could use Bayes's Theorem and get different results.
wiki/Bayesian probability basically says that “probability” is subjective. It's your best guess for how likely something is. But to be Bayesian, your “best guess” must take the observable evidence into account. Updating your beliefs by looking at the outside world is called “Bayesian inference”. Your initial guess about the probability is called your “prior belief”, or just your “prior” for short. Your final guess, after you look at the evidence, is called your “posterior.” The observable evidence is what changes your prior into your posterior.
Formula
From the previous formula, is it possible to deduce the famous formula of Bayes: the Probability of event A happening given that event B has already happened.
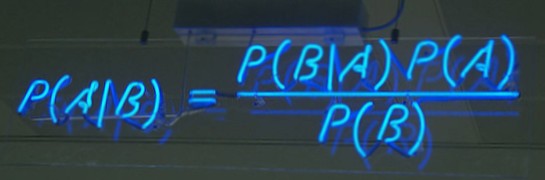
<math> P(A|B) = \frac{\displaystyle P(B|A) P(A)}{\displaystyle P(B)} </math>

Views
Broadly speaking, there are two views on Bayesian probability that interpret the probability concept in different ways. The objective and subjective variants of Bayesian probability differ mainly in their interpretation and construction of the prior probability.
Objectivist
According to the objectivist view, the rules of Bayesian statistics can be justified by requirements of rationality and consistency and interpreted as an extension of logic.
For objectivists, probability objectively measures the plausibility of propositions, i.e. the probability of a proposition corresponds to a reasonable belief everyone (even a “robot”) sharing the same knowledge should share in accordance with the rules of Bayesian statistics, which can be justified by rationality and consistency.
Many modern machine learning methods are based on objectivist Bayesian principles.
In the objectivist stream, the statistical analysis depends on only the model assumed and the data analysed. No subjective decisions need to be involved. In contrast, “subjectivist” statisticians deny the possibility of fully objective analysis for the general case.
Subjectivist
According to the subjectivist view, probability quantifies a “personal belief”. For subjectivists, probability corresponds to a 'personal belief'. For subjectivists, rationality and coherence constrain the probabilities a subject may have, but allow for substantial variation within those constraints.
Example
Example 1: Getting cards out of a deck
Probability of getting 2 kings out of a deck of cards.
<MATH> Pr(\text{2 kings}) = \frac{4}{52} * \frac{3}{51} \approx 0.45 \% </MATH>
- Prior Probability: There is 4 kings in the set of 52 cards
- Second Probability: There is only 3 kings in a set of 51 cards
Example 2: Breast cancer Probability
Problem
- 1% of women at age forty who participate in routine screening have breast cancer.
- 80% of women with breast cancer will get positive mammographies.
- 9.6% of women without breast cancer will also get positive mammographies.
A woman in this age group had a positive mammography in a routine screening. What is the probability that she actually has breast cancer?
Groups Form
To put it another way, before the mammography screening, the 10,000 women can be divided into two groups:
Group 1: 100 women with breast cancer.
Group 2: 9,900 women without breast cancer.
Total: 10,000 patients
After the mammography, the women can be divided into four groups:
Group A: 80 women with breast cancer, and a positive mammography.
Group B: 20 women with breast cancer, and a negative mammography.
Group C: 950 women without breast cancer, and a positive mammography.
Group D: 8,950 women without breast cancer, and a negative mammography.
Total : 10,000 patients
Two grid event Forms
Two grid form with event A, event B, and not A and not B.
| Event A Have Cancer (1%) | Non Event A (~A) Do not have cancer (99%) |
|
|---|---|---|
| Event B Positive Test | True Positive: 1% x 80% | False Positive: 99% x 9.6% |
| Non Event B (~B) Negative Test | False Negative: 1% x 20% | True Negative: 99% x 90.4% |
Solution
<MATH> \begin{array}{rrl} P(cancer) & = & 0.01 \\ P(\text{positive test | cancer}) & = & 0.8 \\ P(\text{positive test}) & = & P(\text{positive test} | cancer) * P(cancer) + P(\text{positive test} | no cancer) * P(\text{no cancer}) \\ P(\text{positive test}) & = & 0.8 * 0.01 + 0.096 * 0.99 = 0.103 \\ P(cancer | \text{positive test}) & = & \frac{\displaystyle P(\text{positive test} | cancer) P(cancer)}{\displaystyle P(\text{positive test})} \\ P(cancer | \text{positive test}) & = & \frac{\displaystyle 0.8 * 0.01}{\displaystyle 0.103} = 0.078 \end{array} </MATH>
Example 3 Spam
