Data Quality - Data (cleaning|scrubbing|wrangling)
About
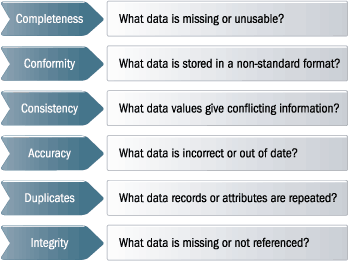
Data cleansing or data scrubbing is the act of:
- detecting (ie data validation)
corrupt or inaccurate records from a record set, table, or database.
Used mainly in databases, the term refers to identifying incomplete, incorrect, inaccurate, irrelevant etc. parts of the data and then replacing, modifying or deleting this dirty data.
The goal is to get data ready for analysis.
After cleansing, a data set will be consistent with other similar data sets in the system. The inconsistencies detected or removed may have been originally caused by different data dictionary definitions of similar entities in different stores, may have been caused by user entry errors, or may have been corrupted in transmission or storage.
Articles Related
Tool
- Stanford's Data Wrangler: an interactive tool for data cleaning and transformation.
- Google's Open Refine tool is a free, open source power tool for working with messy data and improving it.
- Talend provides several open source data quality tools.
Probabilistic
Probabilistic scripts for automating common-sense tasks - The idea is to clean a data set (state, city and rent) automatically through a bayesian probabilistic script that encode prior domain knowledge declaratively such as:
- More populous cities (and states) appear more often
- Pre-bedroom rents in a city and state tend to be similar across listings
- Type named of cities may, rarely, contain a typo.
- Even more rarely, typed names of cities may have multiple typos.
The process is:
- data are fitted to get prior knowledge over cities, states and rents
- domain rules are implemented as follows
- city and state choice are proportional to their frequency in the data set.
- typos are generated via a coin flipping sequence with a chance of 1/10. (There is a chance of 1/10 to get a letter typo, a chance of 1/100 to get two letters typo)
- rent got a little bit of noise by state, city
Script:

More … https://probcomp.github.io/Gen/