
About
Standard Error is a measure of precision for a statistic (slope, intercept or custom calculations).
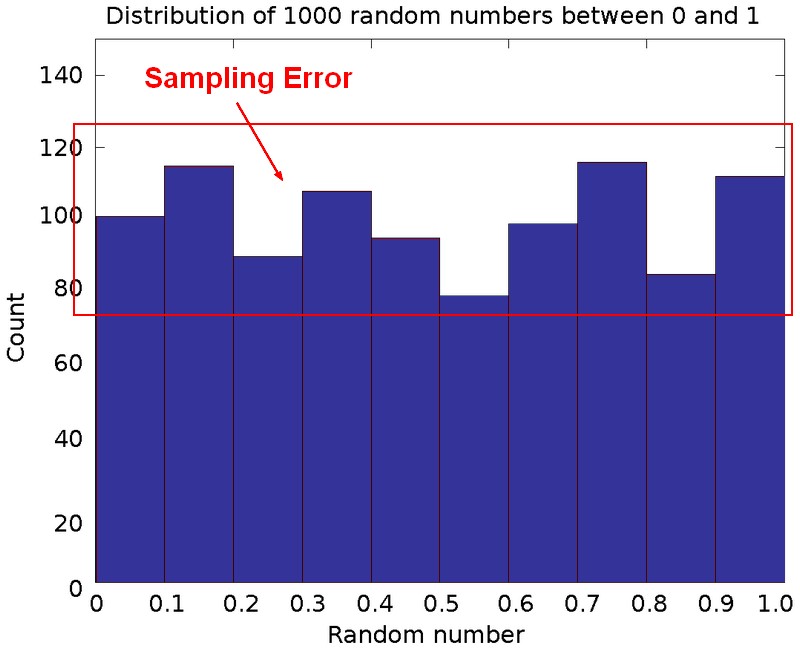
Standard error is an estimate of amount of sampling error as we typically don’t know the population parameters and that we are using a sample.
The standard error of an estimator reflects how it varies under repeated sampling (ie repeated training set).
Standard Error can be seen as the standard deviation of the error distribution. It determines the spread of the x's around the mean.
From two data set from the same population, we can get for the slope 0,5 or - 0.1 for instance. Standard Error permits to say how close is a coefficient to 0.
How much sampling error are we going to get, just due to chance. The standard error defines what you will just get due to chance.
Standard Error is the average amount of sampling error.
Articles Related
Formulas
- Standard error for the Mean: See mean
- Standard error for the coefficient regression: See simple regression
- Standard error for any type of statistics: see Statistics - Bootstrap Resampling
Influence
Standard error and therefore sampling error are determined by:
- Sample size (largely)
- Variance (and therefore the standard deviation) in the population
Bias
Standard error is biased by N as you can see in the formulas. Which means if N is increased: