About
Evaluation is how to determine if the model is a good representation of the truth.
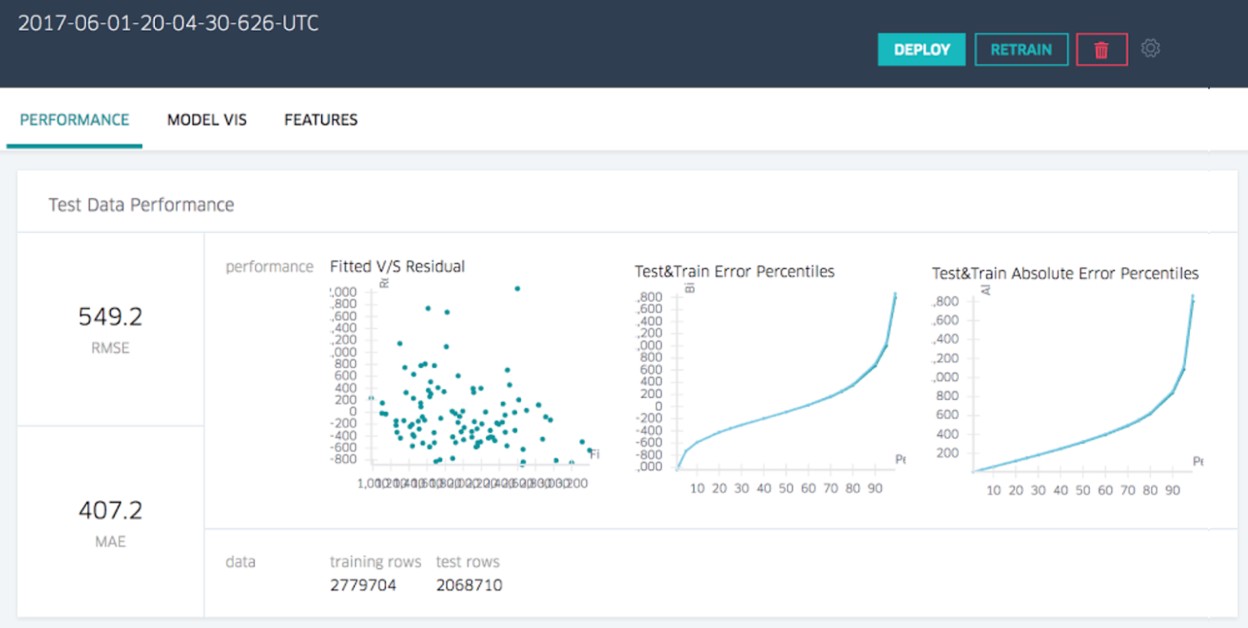
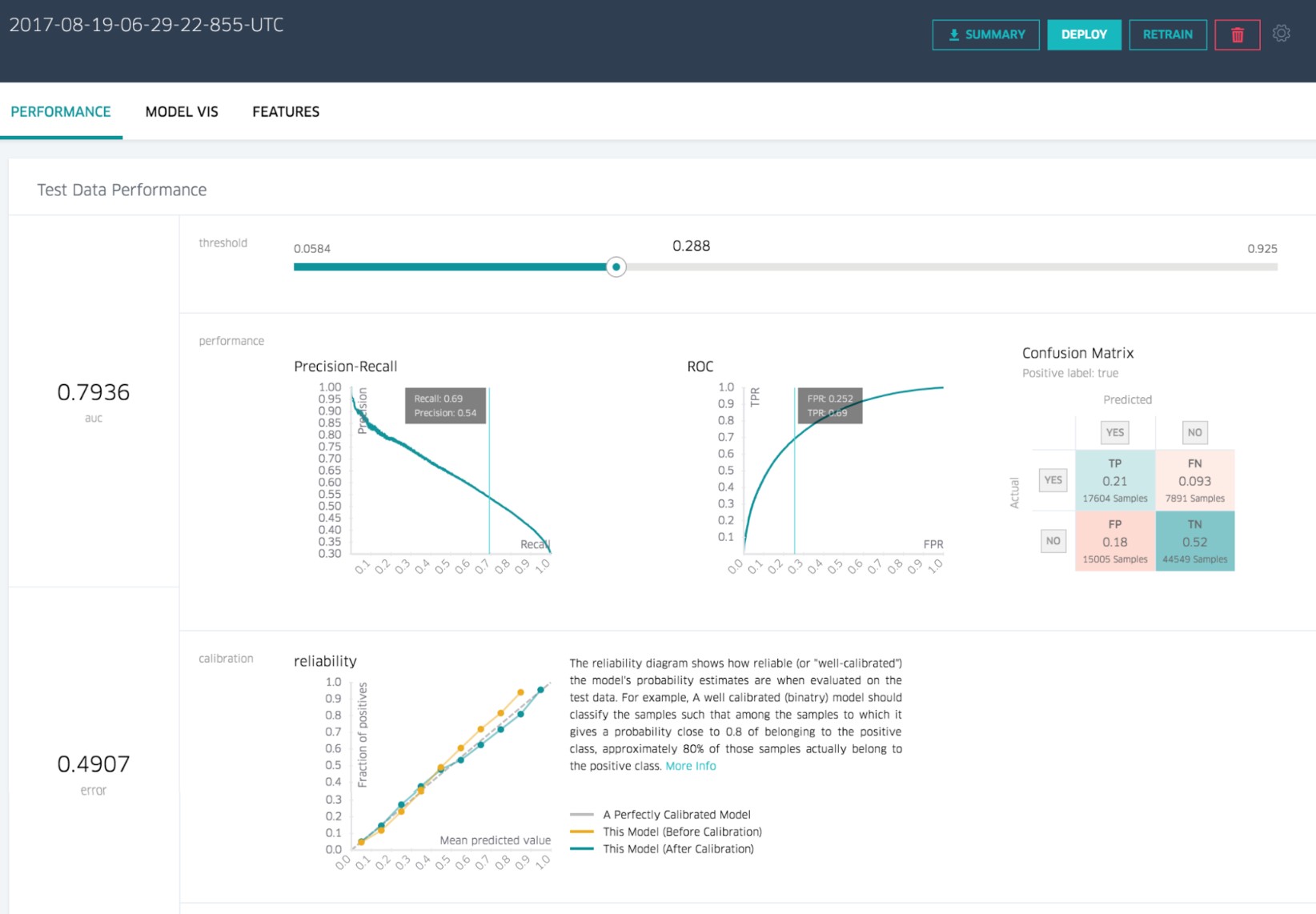
Validation applies the model to test data in order to determine whether the model, built on a training set, is generalizable to other data. In particular, it helps to avoid the phenomenon of overfitting, which can occur when the logic of the model fits the build data too well and therefore has little predictive power.
Validation is a process that help to tell how well does a model in terms of test error
Generally, the Build Activity splits the data into two mutually exclusive subsets:
- the training set for building the model
- the test set use in this validation step in order to evaluate the model
However, if the data is already split into Build and Test subsets, you can specify them.
- Beware of the human tendency to see patterns in random data. See wiki/Apophenia
Articles Related
Metrics
-
- Classifier =
- % of correct predictions
- Regression = Error calculation
- Evaluate the error from a test set where every rating is the average rating for the training set.
Dashboard