Kafka - Topic
About
The Kafka cluster stores streams of records in categories called topics.
A topic is also known as:
- a category
- or feed name.
A topic can have zero, one, or many consumers that subscribe to the data written to it.
Articles Related
Structure
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
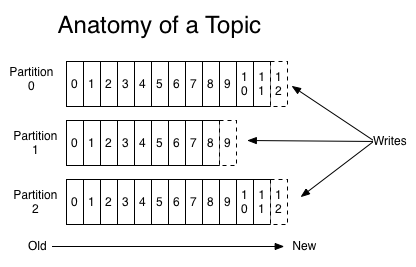
Topic
* -> partition 1
* -> segment 11
* -> segment 12
* -> partition 2
* -> segment 21
* -> segment 22
.......
where:
Management
Creation
- create a topic named “test” with a single partition and only one replica:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
- Other example
$ /usr/bin/kafka-topics --create --zookeeper hostname:2181/kafka --replication-factor 2 --partitions 4 --topic topicname
Docker example where kafka is the service
docker-compose exec kafka kafka-topics --create --topic foo --partitions 1 --replication-factor 1 --if-not-exists --zookeeper localhost:32181
This is one partition and one replica. For a production environment you would have many more broker nodes, partitions, and replicas for scalability and resiliency.
It is possible to create Kafka topics dynamically; however, this relies on the Kafka brokers being configured to allow dynamic topics.
Info
List
bin/kafka-topics.sh --list --zookeeper localhost:2181
Describe
kafka-topics --describe --topic foo --zookeeper localhost:32181
# With docker-compose and the kafka service
docker-compose exec kafka kafka-topics --describe --topic foo --zookeeper localhost:32181
Topic:foo PartitionCount:1 ReplicationFactor:1 Configs:
Topic: foo Partition: 0 Leader: 1 Replicas: 1 Isr: 1
There is one partition and one replica. For a production environment you would have many more broker nodes, partitions, and replicas for scalability and resiliency.
Show Structure
see Kafka - Consumer
Sync
To keep the two topics in sync you can either dual write to them from your client (using a transaction to keep them atomic) or, more cleanly, use Kafka Streams to copy one into the other.
Retention period
For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.