
About
The runtime distributed mode of connect when running/starting a worker
Management
Metadata (Internal topics)
Start
Command line
bin/connect-distributed worker.properties
# Example - Configuration that works well with Kafka and Schema Registry services running locally, no more than one broker
$ ./bin/connect-distributed ./etc/schema-registry/connect-avro-distributed.properties
where:
- worker.properties is the configuration file
New workers will either start a new group or join an existing one based on the worker properties provided.
The connector configuration is not given at the command line because coordination is required between workers. See below connector
Docker
docker run -d \
--name=kafka-connect \
--net=host \
-e CONNECT_PRODUCER_INTERCEPTOR_CLASSES=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor \
-e CONNECT_CONSUMER_INTERCEPTOR_CLASSES=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor \
-e CONNECT_BOOTSTRAP_SERVERS=localhost:29092 \
-e CONNECT_REST_PORT=28082 \
-e CONNECT_GROUP_ID="quickstart" \
-e CONNECT_CONFIG_STORAGE_TOPIC="quickstart-config" \
-e CONNECT_OFFSET_STORAGE_TOPIC="quickstart-offsets" \
-e CONNECT_STATUS_STORAGE_TOPIC="quickstart-status" \
-e CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR=1 \
-e CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR=1 \
-e CONNECT_STATUS_STORAGE_REPLICATION_FACTOR=1 \
-e CONNECT_KEY_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_VALUE_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_INTERNAL_KEY_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_INTERNAL_VALUE_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_REST_ADVERTISED_HOST_NAME="localhost" \
-e CONNECT_LOG4J_ROOT_LOGLEVEL=DEBUG \
-e CONNECT_LOG4J_LOGGERS=org.reflections=ERROR \
-e CONNECT_PLUGIN_PATH=/usr/share/java \
-v /tmp/quickstart/file:/tmp/quickstart \
confluentinc/cp-kafka-connect:4.0.0
Failure
When a worker fails, tasks are rebalanced across the active workers. When a task fails, no rebalance is triggered as a task failure is considered an exceptional case.
If you add a worker, shut down a worker, or a worker fails unexpectedly, the rest of the workers detect this and automatically coordinate to redistribute connectors and tasks across the updated set of available workers.
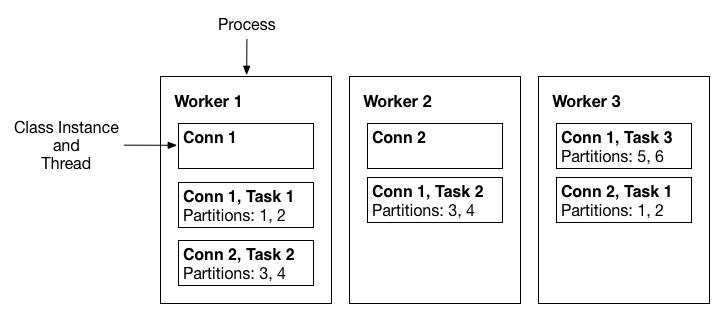
Configuration Management
Worker
See
Cluster
Distributed workers that are configured with matching group.id values in their configuration file automatically discover each other and form a cluster.
All worker configurations must have matching:
- config.storage.topic,
- offset.storage.topic,
- and status.storage.topic properties.
Locally
In distributed mode, if you run more than one worker per host (for example, if you are testing distributed mode locally during development), the following settings must have different values for each instance:
- rest.port - the port the REST interface listens on for HTTP requests
Connector
Creation
Rest
To create a connector, you start the workers and then make a REST request to create/manage a connector
Example: FileSinkConnector where the worker has been started on localhost
curl -X POST -H "Content-Type: application/json" --data @config.json http://localhost:8083/connectors
- or inline
curl -X POST -H "Content-Type: application/json" --data '{"name": "local-file-sink", "config": {"connector.class":"FileStreamSinkConnector", "tasks.max":"1", "file":"test.sink.txt", "topics":"connect-test" }}' http://localhost:8083/connectors
Use the REST API to deploy and manage the connectors when running in distributed mode. See connect-managing-distributed-mode
Confluent cli
With the cli. Load a bundled connector with a predefined name or custom connector with a given configuration.
Upon success it will print the connector’s configuration.
confluent load [<connector-name> [-d <connector-config-file>]]
where:
- connector-name is the id of the connector (which is its name). If the config file has it, it will be overwritten with the command line value.
- connector-config-file can be a properties or json files. If not specified, default to /etc/kafka/connect-<connector-name>.properties.
Example:
confluent load file-source
# same as
confluent load file-source -d /etc/kafka/connect-file-source.properties
{
"name": "file-source",
"config": {
"connector.class": "FileStreamSource",
"tasks.max": "1",
"file": "test.txt",
"topic": "connect-test",
"name": "file-source"
},
"tasks": []
}
Status
Connectors and their tasks publish status updates to a shared topic (configured with status.storage.topic) which all workers in the cluster monitor.
You can see the signification of the state here.
# All connectors
confluent status connectors
# One connector
confluent status connectorName
{
"name": "connectorName",
"connector": {
"state": "RUNNING",
"worker_id": "127.0.0.1:8083"
},
"tasks": [
{
"state": "RUNNING",
"id": 0,
"worker_id": "127.0.0.1:8083"
}
]
}
Because of the rebalancing that happens between worker tasks every time a connector is loaded, a call to confluent status <connector-name> might not succeed immediately after a new connector is loaded. Once rebalancing completes, such calls will be able to return the actual status of a connector.
List
Predefined Connectors
Predefined Connectors are just properties file in /etc/kafka
With the cli:
confluent list connectors
Bundled Predefined Connectors (edit configuration under etc/):
elasticsearch-sink
file-source
file-sink
jdbc-source
jdbc-sink
hdfs-sink
s3-sink
Running connectors
confluent status connectors>
[
"file-source"
]
Unload / Stop ?
confluent unload <connector-name>