About
The 'cube' is just a metadata construct.
You use the Cube operator to source data from or load data into cubes.
When you load a cube, you map the data flow from the source to the attribute that represents the business identifier of the referencing level. Warehouse Builder performs a lookup and then stores the corresponding surrogate ID in the cube table. For example, when you map the attributes from the dimension operator to the cube operator, a Key Lookup operator is created in cases where it is needed to lookup the surrogate identifier of the dimension.
Cubes contain measures and link to one or more dimensions. The axes of a cube contain dimension values and the body of the cube contains measure values. Most measures are numeric and additive. For example, sales data can be organized into a cube whose edges contain values for Time, Product, and Customer dimensions and whose body contains values from the measures Value sales and Dollar sales.
In a relational implementation, a cube is linked to a dimension tables by foreign key constraints and consists of a set of measures.
To create a cube, you must define the following:
- Cube Measures
- Cube Dimensionality
In the Project Explorer panel, expand MyProject > Databases > Oracle. Expand the Name of the database, and then expand Cubes. Right-click on your cube and select Open Editor. (Note: Alternatively, you can also double-click on it.)
Articles Related
Note
If you take a look at the generated SQL, you will find for each dimension, this selection :
( "DIMENSION_X"."DIMENSION_KEY" = "DIMENSION_X"."DIMENSION_ID" ) AND
( "DIMENSION_X"."DIMENSION_ID" IS NOT NULL )
This selection ensure that you select only the detail level and not the hierarchie rows.
Reference
Configuration
Really important if you want to deploy the aggregation
- Deployable: Select TRUE to indicate if you want to deploy this cube. Warehouse Builder generates scripts only for table constraints marked deployable.
- Deployment Options: Use this property to specify where the dimension is deployed. The options are:
- Deploy Aggregations: Deploys the aggregations defined on the cube measures.
- Deploy All: For a relational implementation, the cube is deployed to the database and a CWM definition to the OLAP catalog. For a MOLAP implementation, the cube is deployed to the analytic workspace.
- Deploy Data Objects only: Deploys the cube only to the database. You can select this option only for cubes that have a relational implementation.
- Deploy to Catalog only: Deploys the CWM definition to the OLAP catalog only. Use this option if you want applications such as BI Beans or Discoverer for OLAP to access the dimension data after you deploy data only.
- Materialized View Index Tablespace: The name of the tablespace that stores the materialized view indexes.
- Materialized View Tablespace: The name of the tablespace that stores the materialized view created for the cube.
Additionnal from Metalink : 'Deploy to catalog only' for dimensional objects means the CWM2 ROLAP catalog will be used if it is a relational implementation. 'Deploy data objects only' means DDL objects will be used; tables (for cube and dimension) plus relational dimension. You do not need 'Deploy All' for building an EUL on top of the relational tables, however if you want to use the OLAP integration in D4O then the CWM2 metadata would be used at this point.
Properties
The cube operator has the following properties that you can use to load a cube :
General Properties
- Target Load Order: OWB - Target Operator Name Properties
Cube AW Properties
- AW Truncate Before Load : Indicates whether all existing cube values should be truncated before loading the cube. Setting this property to YES truncates existing cube data.
- AW Staged Load: If true, the set-based AW load data is staged into a temporary table before loading into the AW.
- AW Name : AW Name which contains this Dimension (???)
Cube Policies
- Incremental Aggregation: Select this option to perform incremental loads. This means that if the cube has been solved earlier, subsequent loads will only aggregate the new data.
- Solve the Cube: Select YES for this property to aggregate the cube data while loading the cube. This increases the load time, but decreases the query time. The data is first loaded and then aggregated.
Cube Load Properties
Dimension
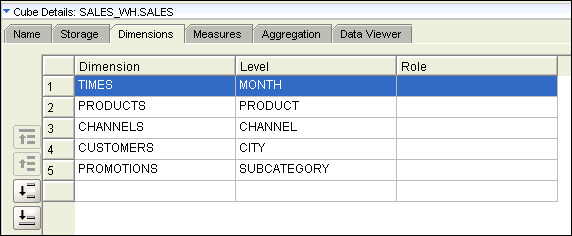
To examine the dimensionality of the cube, click the Dimensions tab in the Cube Details panel of the Data Object Editor.
Observe that the SALES cube is linked to levels within the five dimensions.
For example, SALES cube refers to PRODUCT level of the PRODUCTS dimension. The Role column displays in a drop-down list, the dimension roles (if defined previously) that the selected dimension contains.
The table on the Dimensions tab contains the following columns:
- Dimension: This field represents the name of the dimension that the cube references. Click the Ellipsis button in this field to display the Available Modules dialog box. This dialog box displays the list of dimensions in the current project. Select a dimension from this list. Warehouse Builder filters the dimensions displayed in this list based on the storage type specified for the cube. If you define a relational implementation for the cube, only those dimensions that use a relational implementation are displayed. If you define a MOLAP implementation for the cube, only the dimensions that use a MOLAP implementation are displayed.
- Level: The Levels displays all the levels in the dimension selected in the Dimension field. Select the dimension level that the cube references.
- Role: The Role list displays the dimension roles, if any, that the selected dimension contains. Select the dimension role that the cube uses. You can specify dimension roles for relational dimensions only.
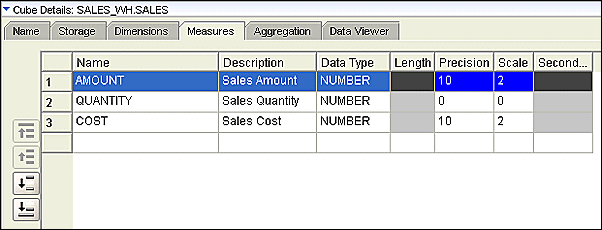
Measures
To examine the measures of the cube, click the Measures tab in the Cube Details panel. Note that there are three measures and all of them are numeric.
These measures can be aggregated to determine the total sales cost, amount, or quantity across a period of time or for a particular customer or for a particular product.
Aggregation
Use the Aggregation tab to define the aggregations that must be performed for each dimension that the cube references. You select the aggregate function that is used to aggregate data. You can also precompute measures along each dimension that the cube references. By default, aggregation is performed for every alternate level starting from the lowest level. The default aggregate function is SUM.
You specify the following:
- Cube Aggregation Method: Select the aggregate function used to aggregate the cube data. The default selection is SUM.
- Summary Refresh Method: Select the data refresh method. The options you can select are On Demand and On Commit.
- Summary Strategy for Cube: Define the levels along which data should be precomputed for each dimension.

Summary Strategy for Cube Use this section to define levels along which data should be precomputed for each dimension. The Dimension column lists the dimensions that the cube references. To select the levels in a dimension for which data should be precomputed, click the Ellipsis button in the PreCompute column to the right of the dimension name. The PreCompute dialog box is displayed. Use this dialog box to select the levels in the dimension along which the measure data is precomputed. You can specify the levels to be precomputed for each dimension hierarchy. By default, alternate levels, starting from the lowest level, are precomputed.
Some of the aggregate data is generated during deployment and the rest is aggregated on the fly in response to a query, following the rules defined in the Aggregation tab.
Precomputing MOLAP Cubes
For MOLAP implementations, the aggregate data is generated and stored in the analytic workspace along with the base-level data. You cannot define aggregations for pure relational cubes (cubes implemented in a relational schema in the database only and not in OLAP catalog). For more details on the strategies for summarizing data, see the chapter about summarizing data in the Oracle OLAP User's Guide.
Precomputing ROLAP Cubes
For ROLAP cubes, aggregation is implemented by creating materialized views that store aggregated data. These materialized views improve query performance.
The materialized views created to implement ROLAP aggregation are not displayed under the Materialized Views node in the Project Explorer.
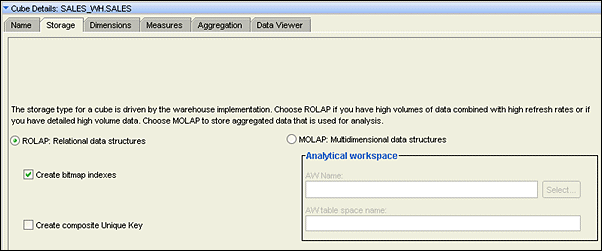
Storage
You can implement a cube :
- in a relational form
- or a multidimensional form in the database.
In relational implementation, a relational table stores the cube data. When a cube is implemented in a multidimensional environment, the cube data is stored in an analytic workspace.
If you want to modify the physical implementation of the cube, click the Storage tab in the Cube Details panel. You can select between relational or multidimensional implementation.
For relational implementation of the cube, you can opt to create bitmap indexes. Having these indexes on the cube improves your performance at query time.
Support
Load only a part of the data set
The loading process in a cube do a join with the dimensions.
"D_DIMENSION_X"."DIMENSION_CODE" = "INGRP1"."D_DIMENSION_CODE" )
Thus, you can have no problem even if a dimension code is missing in the dimension table. I had the problem with the time dimension and it's very paintfull to find.
ORA-06510: PL/SQL: unhandled user-defined exception
Deployment of cube fails with the following errors:
ORA-06510: PL/SQL: unhandled user-defined exception
ORA-06512: at "OLAPSYS.CWM2_OLAP_CUBE", line 99
ORA-06512: at line 2
See Metalink Note.
To debug this kind of issue, save the generated OWB CWM2 script to a file, then before you run on the target schema;
C:\Documents and Settings\Nicolas>sqlplus targetuser@database
SQL*Plus: Release 10.2.0.4.0 - Production on Fri Jan 9 12:03:35 2009
Copyright (c) 1982, 2007, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining Scoring Engine and Real Application Testing options
SQL> set serveroutput on size 999999
SQL> exec cwm2_olap_manager.set_echo_on
PL/SQL procedure successfully completed.
SQL> @location/your_file
AMD-00101 cannot create Cube "QS_DWH.C_SOR_CONSUMERS_SALES"; metadata entity
already exists
AMD-00101 cannot create Cube "QS_DWH.C_SOR_CONSUMERS_SALES"; metadata entity
already exists
AMD-00101 cannot create Cube "QS_DWH.C_SOR_CONSUMERS_SALES"; metadata entity
already exists
BEGIN
*
ERROR at line 1:
ORA-06510: PL/SQL: unhandled user-defined exception
ORA-06512: at "OLAPSYS.CWM2_OLAP_CUBE", line 99
ORA-06512: at line 2
Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining Scoring Engine and Real Application Testing options
Optionnaly, you can find the list of the AMD message on Metalink