About
Storing data in columns is functionally similar to having a built-in index for each column.
This data structure is used in analytics and NoSql database.
Columnar storage is a popular data structure in analytical workloads because of the vertical pruning, parallel processing and compression benefits.
The goal is to keep I/O to a minimum by reading from a disk only the data required for the query.
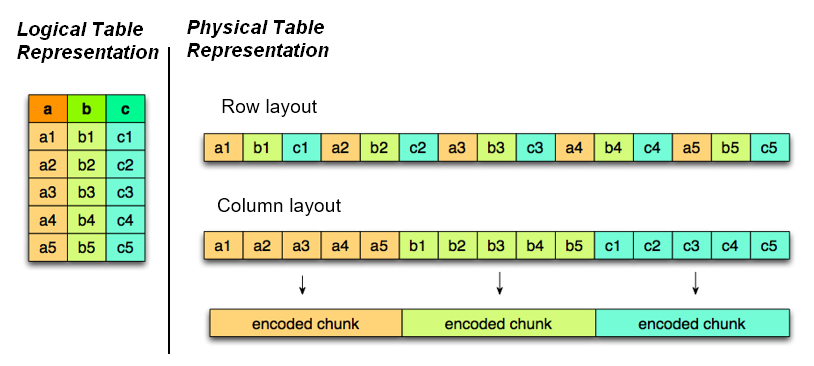
Concept
Compression
compression is really more efficient as you are more likely to have more duplicate in a column than in a row.
Since all the values in a given column have the same type, generic compression tends to work better and type-specific compression can be applied.
Parallel
In a column storage, data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core.
Index
Columnar storage, in many cases, eliminates the need for additional index structures. Storing data in columns is functionally similar to having a built-in index for each column (bit map or b-tree ?)
High Locality
With columnar data, operations on single columns, such as searching or aggregations, can be implemented as loops over an array stored in contiguous memory locations. Such an operation has high spatial locality and can efficiently be executed in the CPU cache. With row-oriented storage, the same operation would be much slower because data of the same column is distributed across memory and the CPU is slowed down by cache misses.
Filter Early From Disk
Since column values are stored consecutively, a query engine can skip loading columns whose values it doesn’t need to answer a query, and use vectorized operators on the values it does load.
Vertical Partition Pruning
scan only a subset of the columns.
Branching more predictable
Instruction branching can be made more predictable by choosing a better encodings that suits the modern processors’ pipeline.
RDBMS
- Oracle, SAP Hana
- Vertica
| Vendor | Product | Differentiators |
|---|---|---|
| Calpont | CNX Data Warehouse Platform | Compatible with existing Oracle database environments. Modular architecure for incremental scaling |
| Exasol | EXASolution | A leader in 100 GB and 1000 GB TCP-H benchmark tests |
| InfoBright | Brighthouse | Data pack storage approach for data-optimized compression for smaller footprint. Queries focus on relevant packs for faster performance. |
| ParAccel | ParAccel Analytic Database | Combines column-store architecture with in-memory anaysis capabilities for fastperformance. Offers “drop-in accelerator” configurations on top of popular relational databases. |
| Sand Technology | Sand/DNA Software | Extensions available for Oracle, IBM DB2, SAP NetWeaver BI |
| Sybase | Sybase IQ | Category leader and early pioneer with 1,000-plus customers |
| Vertica | Vertica Database | Supports continuous data loading. Also offers appliance based on HP hardware/Red Hat Linux OS-based database appliance. |