Language - (Syntax|Structural) Tree
About
The graphical representations of a grammar are called Syntax or Structural tree.
Whether your language input is (Markdown, HTML, or prose, ..), it needs to be parsed to a workable format. Such a format is called a syntax tree.
There is actually two well-known trees:
- The concrete syntax tree (CST) (or parse tree). A low-level representation of the grammar that represent every detail (such as white-space in white-space insensitive languages)
- and the abstract syntax tree (AST). A high-level representation of the grammar structures that only represent details relating to the syntactic structure of code (such as ignoring whether a double or single quote was used in languages).
Example
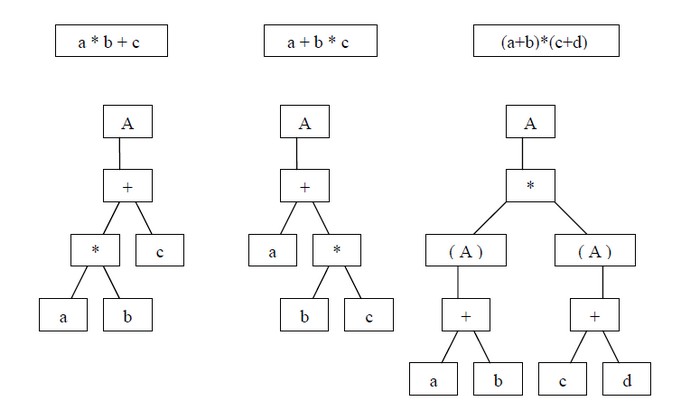
Concret Syntax Tree (CST) vs Abstract Syntax Tree (AST)
In short, a A CST has all information needed to restore the original document completely, AST does not.
For example for an HTML document, CSTs house info on style such as tabs or spaces, but ASTs do not. This makes ASTs often easier to work with.
ASTs can still recreate an exact syntactic representation.
A parse tree (CST) is a record of the rules (and tokens) used to match some input text whereas a abstract syntax tree records the structure of the input and is insensitive to the grammar that produced it.
There are an infinite number of grammars for any single language and hence every grammar will result in a different tree form because of all the intermediate rules.
An abstract syntax tree is a far superior intermediate form precisely because of this insensitivity and because it highlights the structure of the language not the grammar.
It's best to look at an example. For input 3+4 you really want to use the following intermediate form:
+
| \
3 4
That is, the operator at the root and 3 and 4 as operands (children). In child-sibling form, you'd have
+
|
3 -- 4
Ok, so now a parse tree. I'll pick an extremely simple one out of the infinite number:
expr
|
plus
| \ \
3 + 4
Usage
A syntax tree (from a compiler,…) may be used to perform:
- static semantic analyses like checking that all variables are defined.
- code generation (type-checking, code optimization, flow analysis, checking for variables being assigned values before they’re used, and so on)
- pretty-printing (ie Syntax Formatting)
- program restructuring,
- code instrumentation,
- and computing various metrics of a program.
Most of these operations will need to treat nodes that represent assignment statements differently from nodes that represent variables or arithmetic expressions.
Specification
Documentation / Reference
- Gamma, Erich; Helm, Richard; Johnson, Ralph; Vlissides, John (1994-10-31). Design Patterns: Elements of Reusable Object-Oriented Software (Kindle Locations 5190-5195). Pearson Education.