Web - Robots (Wanderers | Crawlers | Spiders)
About
This page is about Bot in a web context.
Web Robots (also known as Web Wanderers, Crawlers, or Spiders), are crawler program that scan the web generally
- in order to:
- create an search engine. See Search Engine - Bot
- or seo tools
- but the majority of them have malicious intents (trying to steal, penetrate, misuse your web application) see How can I protect myself from Bad Bot (Spambot, Attacker )?)
More than half of all web traffic is made up of bots.
Example of report
Example of bots agent report on this website.
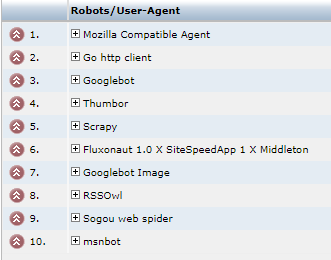
where: user-agent is the user agent given by the robot.
Implementation
bot are generally implemented with a headless browser library.
Management
List
There is a lot of bot out there.
See:
Configuration
Robots.txt
See Robots
Meta
The meta name=“ROBOTS” tell visiting robots whether a document may be indexed, or used to harvest more links.
In the following meta example a robot should neither index this document, nor analyze it for links.
<META name="ROBOTS" content="NOINDEX, NOFOLLOW">
The list of terms in the content is:
- ALL,
- INDEX,
- NOFOLLOW: Don't analyze the page for links. Robot - Follow / NoFollow instruction
- NOINDEX: Don't add the page to the index
Specific to a bot: googlebot cannot index for instance
<meta name="robots" content="nofollow">
<meta name="googlebot" content="noindex">
Header
the If-Modified-Since HTTP header tell Crawler if the content has changed since the last crawl. Supporting this feature saves bandwidth and overhead.
Inspect
Rendering
See how google Bot see you website at GoogleBot rendering
Rendering
For Bot that can not render a javascript dynamic web page (PWA), you can pre-render it with puppeteer. pupperender
Test
A simple test based on Javascript - Regular expression (Regexp) based on their user agent string
bots = /bot|crawler|spider|crawling/i;
let isBot = bots.test(navigator.userAgent);
if (!isBot) {
console.log('This agent is not a bot ('+navigator.userAgent+')' );
}
Mobile first
https://webmasters.googleblog.com/2016/11/mobile-first-indexing.html