About
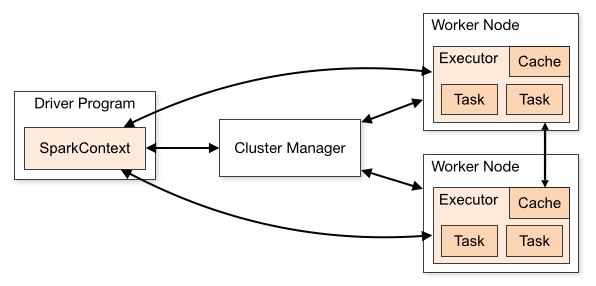
When running on a cluster, each Spark application gets an independent set of executor JVMs that only run tasks and store data for that application.
Worker or Executor are processes that run computations and store data for your application.
Worker programs run:
- or in local threads
There's no communication between workers. See Spark - Cluster
When you perform transformations and actions that use functions, Spark will automatically push a closure containing that function to the workers so that it can run at the workers. One closure is send per worker for every task.
Any modifications to the global variables at the workers are not sent to the driver or to other workers.
Articles Related
Concept
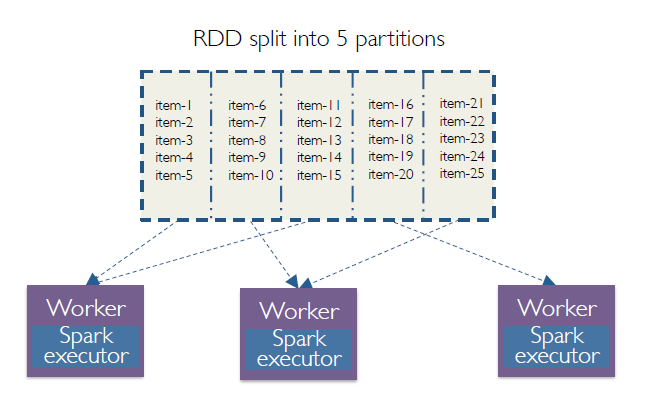
Partition and executor
5 partitions and 3 executors.
Management
Memory
Spark - Configuration spark.executor.memory
Example with spark-shell
spark-shell --conf "spark.executor.memory=4g"
Core
Number of thread (ie core)
Spark - Configuration. spark.executor.cores