
Spark - Application
About
An application is an instance of a driver created via the initialization of a spark context (RDD) or a spark session (Data Set)
This instance can be created via:
- a whole script (called batch mode)
Within each Spark application, multiple jobs may be running concurrently if they were submitted by different threads.
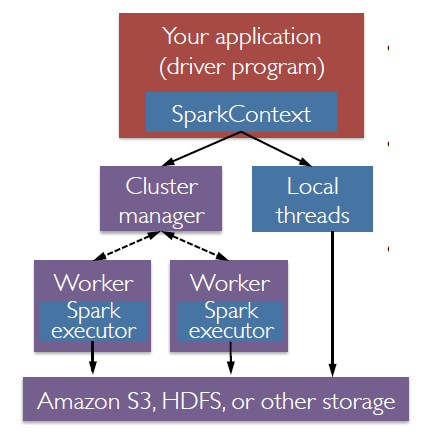
A typical script starts with a session (context) and defines:
that are table/like object where you can perform data operation.
See self-contained-applications
Articles Related
Example
See:
Management
Properties
Properties are seen as configuration.
See Application properties such as application name, …
- In the code
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("CountingSheep")
val sc = new SparkContext(conf)
- At the command line with spark-submit
// empty conf in the code
val sc = new SparkContext(new SparkConf())
./bin/spark-submit --name "My app" --master local[4] --conf spark.eventLog.enabled=false --conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" myApp.jar
Name
The name is used for instance in the name of the log file
Submit
spark-submit
The spark-submit script is used to launch applications:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
Python and R -(from quickstart):
# For Python examples, use spark-submit directly:
./bin/spark-submit examples/src/main/python/pi.py
# For R examples, use spark-submit directly:
./bin/spark-submit examples/src/main/r/dataframe.R
livy
See livy - http://gethue.com/how-to-use-the-livy-spark-rest-job-server-api-for-submitting-batch-jar-python-and-streaming-spark-jobs/
Kill
- Spark standalone or Mesos with cluster deploy mode
spark-submit --kill [submission ID] --master [spark://...]
- Java
./bin/spark-class org.apache.spark.deploy.Client kill <master url> <driver ID>
Status
- Spark standalone or Mesos with cluster deploy mode
spark-submit --status [submission ID] --master [spark://...]