Spark - Cluster
About
A cluster in Spark has the following component:
- A spark application composed of a driver program which include the SparkContext (for RDD) or the Spark Session for a data frame which connect to a cluster manager, get the worker (executor) and manage them.
- A cluster manager that Spark use to get executor
- Each executor has a cache

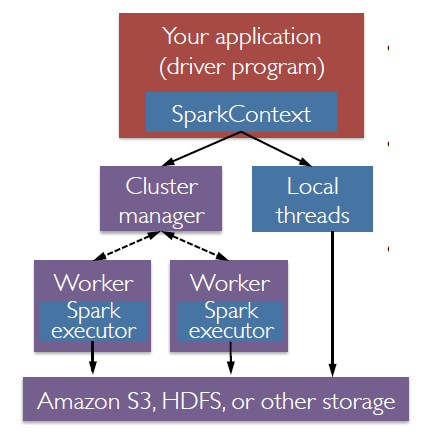
At a high level, every Apache Spark application consists of a driver program that launches various parallel operations on executor Java Virtual Machines (JVMs) running either in a cluster or locally on the same machine.
Articles Related
Daemon
Manager
Spark is agnostic to the underlying cluster manager.
The system currently supports this cluster managers:
- Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos – a general cluster manager that can also run Hadoop MapReduce and service applications.
- Hadoop YARN – the resource manager in Hadoop 2.
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.
The cluster manager is given through the master property.