About
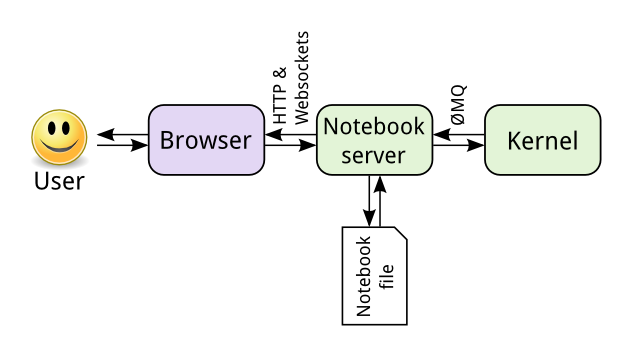
Sparkmagic is a kernel that provides Ipython magic for working with Spark clusters through Livy in Jupyter notebooks.
Installation Steps
Package Installation
- Start a shell with admin right (The anaconda shell if you have installed Jupyter with Anaconda)
pip install sparkmagic
- Show
pip show sparkmagic
Name: sparkmagic
Version: 0.12.5
Summary: SparkMagic: Spark execution via Livy
Home-page: https://github.com/jupyter-incubator/sparkmagic
Author: Jupyter Development Team
Author-email: [email protected]
License: BSD 3-clause
Location: c:\anaconda\lib\site-packages
Requires: autovizwidget, pandas, nose, requests, tornado, hdijupyterutils, numpy, ipython, ipykernel, notebook, ipywidgets, requests-kerberos, mock
Enable Extensions
- Enable/be sure of ipywidgets extension
jupyter nbextension enable --py --sys-prefix widgetsnbextension
Enabling notebook extension jupyter-js-widgets/extension...
- Validating: ok
Install the wrapper kernels.
# Location from sparkmagic package info ''pip show sparkmagic''
cd c:\anaconda\lib\site-packages
jupyter-kernelspec install sparkmagic/kernels/sparkkernel
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel
jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel
jupyter-kernelspec install sparkmagic/kernels/sparkrkernel
[InstallKernelSpec] Installed kernelspec sparkkernel in C:\ProgramData\jupyter\kernels\sparkkernel
[InstallKernelSpec] Installed kernelspec pysparkkernel in C:\ProgramData\jupyter\kernels\pysparkkernel
[InstallKernelSpec] Installed kernelspec pyspark3kernel in C:\ProgramData\jupyter\kernels\pyspark3kernel
[InstallKernelSpec] Installed kernelspec sparkrkernel in C:\ProgramData\jupyter\kernels\sparkrkernel
Enable the sparkmagic extension
- Enable the server extension so that clusters can be programatically changed
jupyter serverextension enable --py sparkmagic
Enabling: sparkmagic
- Writing config: C:\Users\gerardn\.jupyter
- Validating...
sparkmagic ok
Configure (config.json)
If you are creating/modifying this file, you need to restart the server
- Create the config home
mkdir %USERPROFILE%/.sparkmagic
mkdir ~/.sparkmagic
- Create in it the config.json configuration file.
Example on a not secured cluster (from config.json)
Endpoint:
- Authentication method auth may be:
- None
- Kerberos
- Basic_Access
{
"kernel_python_credentials" : {
"username": "nico",
"password": "pwd",
"url": "http://10.10.6.30:8998",
"auth": "Basic_Access"
},
"kernel_scala_credentials" : {
"username": "nico",
"password": "",
"url": "http://10.10.6.30:8998",
"auth": "None"
},
"kernel_r_credentials": {
"username": "nico",
"password": "",
"url": "http://10.10.6.30:8998"
},
"logging_config": {
"version": 1,
"formatters": {
"magicsFormatter": {
"format": "%(asctime)s\t%(levelname)s\t%(message)s",
"datefmt": ""
}
},
"handlers": {
"magicsHandler": {
"class": "hdijupyterutils.filehandler.MagicsFileHandler",
"formatter": "magicsFormatter",
"home_path": "~/.sparkmagic"
}
},
"loggers": {
"magicsLogger": {
"handlers": ["magicsHandler"],
"level": "DEBUG",
"propagate": 0
}
}
},
"wait_for_idle_timeout_seconds": 15,
"livy_session_startup_timeout_seconds": 60,
"fatal_error_suggestion": "The code failed because of a fatal error:\n\t{}.\n\nSome things to try:\na) Make sure Spark has enough available resources for Jupyter to create a Spark context.\nb) Contact your Jupyter administrator to make sure the Spark magics library is configured correctly.\nc) Restart the kernel.",
"ignore_ssl_errors": false,
"session_configs": {
"driverMemory": "1000M",
"executorCores": 2
},
"use_auto_viz": true,
"coerce_dataframe": true,
"max_results_sql": 2500,
"pyspark_dataframe_encoding": "utf-8",
"heartbeat_refresh_seconds": 30,
"livy_server_heartbeat_timeout_seconds": 0,
"heartbeat_retry_seconds": 10,
"server_extension_default_kernel_name": "pysparkkernel",
"custom_headers": {
"X-Requested-By": "admin"
},
"retry_policy": "configurable",
"retry_seconds_to_sleep_list": [0.2, 0.5, 1, 3, 5],
"configurable_retry_policy_max_retries": 8
}
Validate
- You can see in the log that Sparkmagic is enabled when starting the notebook server
jupyter notebook
[I 17:39:43.691 NotebookApp] [nb_conda_kernels] enabled, 4 kernels found
[I 17:39:43.696 NotebookApp] Writing notebook server cookie secret to C:\Users\gerardn\AppData\Roaming\jupyter\runtime\notebook_cookie_secret
[I 17:39:47.055 NotebookApp] [nb_anacondacloud] enabled
[I 17:39:47.091 NotebookApp] [nb_conda] enabled
[I 17:39:47.605 NotebookApp] ✓ nbpresent HTML export ENABLED
[W 17:39:47.606 NotebookApp] ✗ nbpresent PDF export DISABLED: No module named 'nbbrowserpdf'
[I 17:39:48.112 NotebookApp] sparkmagic extension enabled!
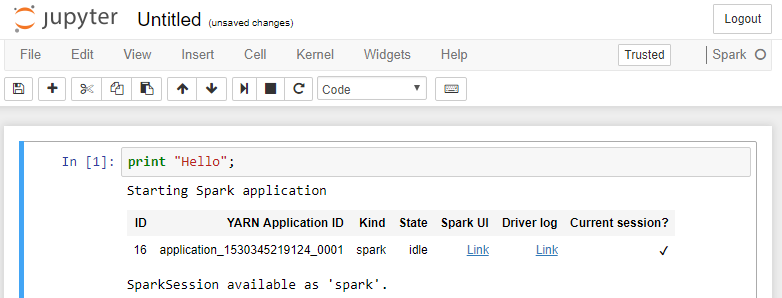
- Start a driver
print "Hello";
Magics By Kernel
iPython - Magic Function by kernel
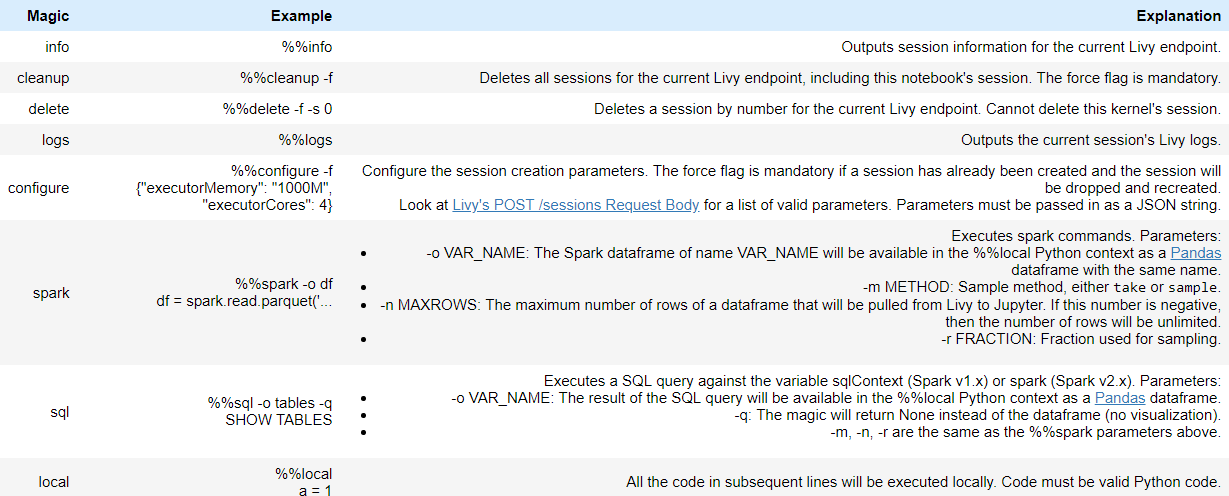
magics are special commands that you can call with %%
%%MAGIC <args>
IPython
From a ipython kernel
Example from magics in IPython Kernel.ipynb
- Load the Sparkmagic
%load_ext sparkmagic.magics
- The %%manage_spark line magic lets you manage Livy endpoints and Spark sessions.
%manage_spark
%spark?
%spark logs -s testsession
- sql
%%spark -c sql
SHOW TABLES
%%spark -c sql -o df_hvac --maxrows 10
SELECT * FROM hivesampletable
- Use the Pandas dataframe df_hvac created above via the -o option
df_hvac.head()
PySpark
https://github.com/jupyter-incubator/sparkmagic/blob/master/examples/Pyspark%20Kernel.ipynb
Context
The contexts are automatically created. There is no need to create them. ie
sc = SparkContext('yarn-client')
sqlContext = HiveContext(sc)
spark = SparkSession \
.builder.appName("yarn-client") \
.getOrCreate()
Dependent of the version, you may have the following variable names:
- spark for SparkSession
- sc for SparkContext
- sqlContext for a HiveContext (SparkContext with hive)
Configure
%%configure -f
{"name":"remotesparkmagics-sample", "executorMemory": "4G", "executorCores":4 }
where:
- -f change the running session
- name is the application name and should start with remotesparkmagics to allow sessions to get automatically cleaned up if an error happened.
Sql
%%sql
use myDatabase
Then…
%%sql
select * from hivesampletable
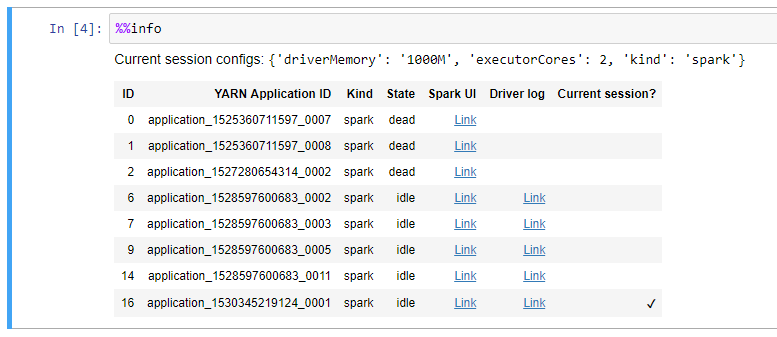
Info
Help
%%help
Support
log
See HOME/.sparkmagic/log
You need to have at least 1 client created to execute commands.
Your kernel has crashed. Restart it ?
Add a jar
With the configure magic:
- Set the jars parameters
- or set the conf spark parameters with the maven coordinates
%% configure
{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.10:1.4.0" }}
For HdInisght, see apache-spark-jupyter-notebook-use-external-packages