
About
Data - Cache in Spark.
Each executor has a cache.
Articles Related
from the Spark - Web UI (Driver UI)
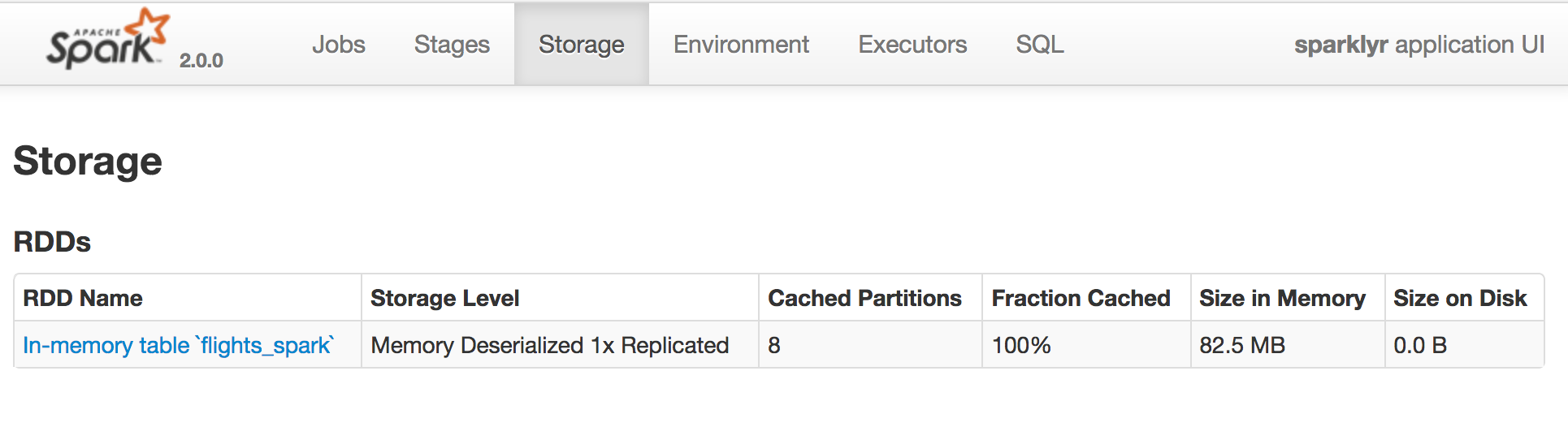
Example
- lines is recomputed
lines = sc.textFile("...", 4)
comments = lines.filter(isComment)
print lines.count()
print comments.count() # lines is recomputed
- lines is NOT recomputed but get from the cache
lines = sc.textFile("...", 4)
lines.cache() # save, lines is NOT recomputed when comments.count() is called
comments = lines.filter(isComment)
print lines.count()
print comments.count()