
About
Installation and configuration of a PySpark (Spark Python) environment on Idea (PyCharm)
Articles Related
Prerequisites
You have already installed locally a Spark distribution. See Spark - Local Installation
Steps
Install Python
- Install Anaconda 2.7 (3.7 is also supported)
- Add it as interpreter inside IDEA
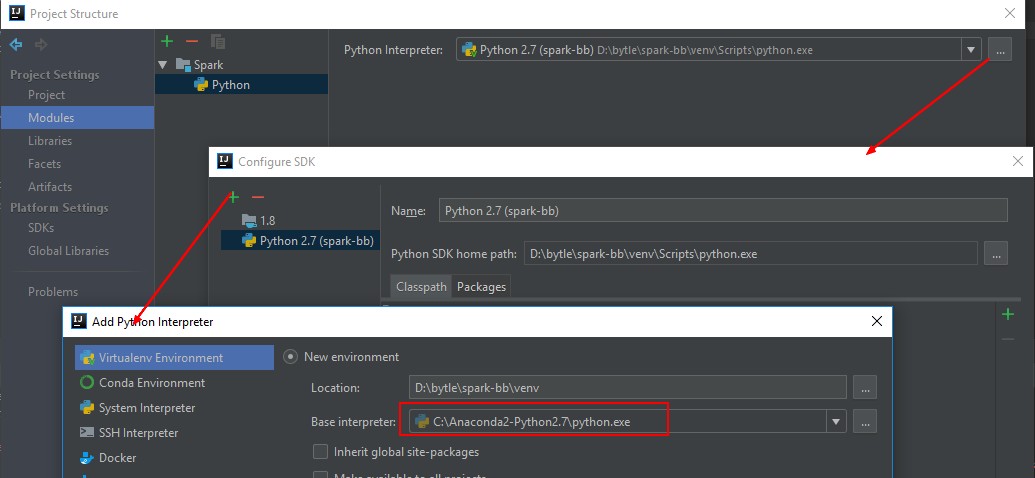
- Add Python as framework
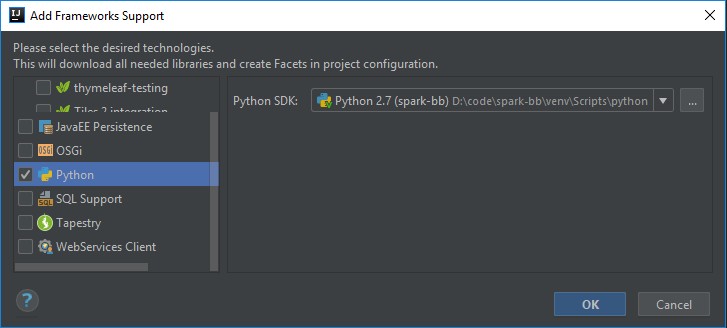
Install Spark
- Install Spark locally. See Spark - Local Installation
- Install pyspark in the virtual environment
cd venv\Scripts
pip install "pyspark=2.3.0"
Collecting pyspark
Collecting py4j==0.10.6 (from pyspark)
Using cached https://files.pythonhosted.org/packages/4a/08/162710786239aa72bd72bb46c64f2b02f54250412ba928cb373b30699139/py4j-0.10.6-py2.py3-none-any.whl
Installing collected packages: py4j, pyspark
Successfully installed py4j-0.10.6 pyspark-2.3.0
or
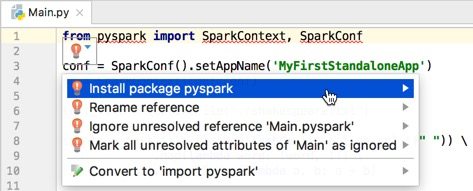
Install third package
- Install psutil to have better support with spilling
cd venv\Scripts
pip install psutil
Collecting psutil
Downloading https://files.pythonhosted.org/packages/b6/ca/2d23b37e9b30908174d2cb596f60f06b3858856a2e595c931f7d4d640c03/psutil-5.4.5-cp27-none-win_amd64.whl (219kB)
100% |################################| 225kB 2.4MB/s
Installing collected packages: psutil
Successfully installed psutil-5.4.5
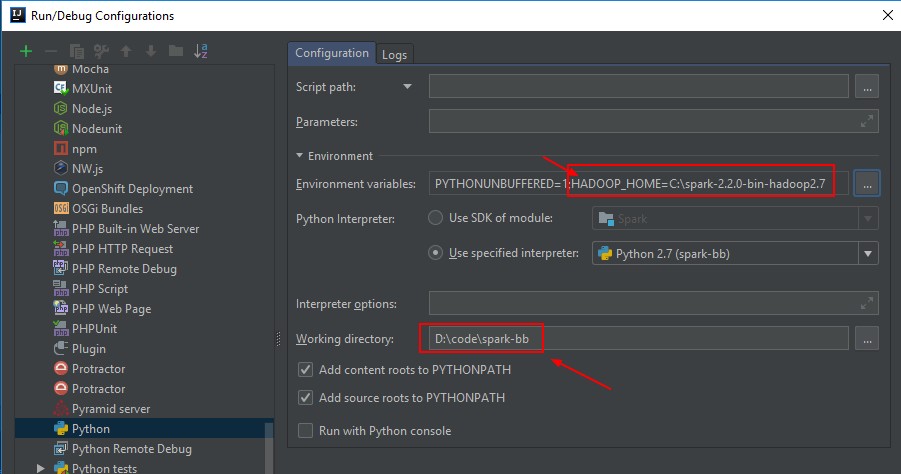
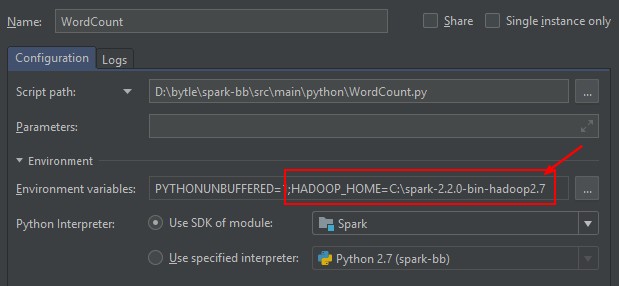
Default Run Configuration
- Change the default run parameters for Python.
- Add the HADOOP_HOME as environment variable (if not set on the OS leve) and set the working directory to your home project.
Do not add SPARK_HOME. It will otherwise call the spark-submit.cmd script and the PYTHONPATH is not set
If you want to set SPARK_HOME, you need also to add the PYTHONPATH. (You can see it in pyspark2.cmd
PYTHONPATH=%SPARK_HOME%\python;%SPARK_HOME%\python\lib\py4j-0.10.4-src.zip;%PYTHONPATH%
PYTHONPATH=C:\spark-2.2.0-bin-hadoop2.7\python\lib\py4j-0.10.4-src.zip;C:\spark-2.2.0-bin-hadoop2.7\python;
Run a test script
- Create a test script (From Setting up a Spark Development Environment with Python) and download the file shakespeare.txt
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('MyFirstStandaloneApp')
sc = SparkContext(conf=conf)
text_file = sc.textFile("./src/main/resources/shakespeare.txt")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
print ("Number of elements: " + str(counts.count()))
- Run the script
- Output
2018-06-04 22:48:32 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Number of elements: 67109
Support
_PYSPARK_DRIVER_CALLBACK_HOST
With this kind of error, you have SPARK_HOME set but you don't the PYTHONPATH
Method showString does not exist
Error:
py4j.Py4JException: Method showString([class java.lang.Integer, class java.lang.Integer, class java.lang.Boolean]) does not exist
You have somewhere SPARK_HOME set but you don't have set PYTHONPATH
Two Resolution possible:
- 1 - Suppress SPARK_HOME
- 2 - or Add PYTHONPATH
Example:
set PYTHONPATH=%SPARK_HOME%\python;%PYTHONPATH%
set PYTHONPATH=%SPARK_HOME%\python\lib\py4j-0.10.4-src.zip;%PYTHONPATH%