
About
A local installation is a spark installation on a single machine (generally a dev machine).
The local master connection will start for you a local standalone spark installation on your machine.
This steps were written for a Windows laptop.
Articles Related
Connection URL
The master connection URL local will start for you locally the standalone spark cluster manager:
- with one thread local
- with N threads local[N]
Example with sparklyr:
sc <- sparklyr::spark_connect(master = "local")
where: master = Spark - Master (Connection URL )
Installation Steps
This a manually installation, you may want also to check the semi-automatic sparklyr installation.
This steps were written for a Windows laptop.
Pre-built unarchive
Download the “Pre-built for Hadoop X.X and later” package of the latest release of Spark and simply unpack it.
They are located at https://d3kbcqa49mib13.cloudfront.net/ to download the version spark-2.2.0-bin-hadoop2.7.tgz you would type: https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
Once it is unpacked, you should be able to run the spark-shell script from the package’s bin directory
Env
SPARK_HOME
The SPARK_HOME environment variable gives the installation directory.
Set the SPARK_HOME environment variable. This environment variable is used to locate
- Winutils (on Windows) in the bin
- the conf file first at SPARK_HOME/conf then at SPARK_HOME/hadoop/conf
SET SPARK_HOME=/pathToSpark
HADOOP_HOME
Set the HADOOP_HOME environment variable. The environment variable is used to locate
- Winutils (on Windows) in the HADOOP_HOME/bin
- the conf file HADOOP_HOME/conf
SET HADOOP_HOME=%SPARK_HOME%\hadoop
Classpath
The conf files are searched within the classpath in this order:
- SPARK_HOME/conf
- HADOOP_HOME/conf
Example of command line when starting the spark sql cli where you can see that the classpath (cp) has two conf location.
java
-cp "C:\spark-2.2.0-bin-hadoop2.7\bin\..\conf\;C:\spark-2.2.0-bin-hadoop2.7\bin\..\jars\*;C:\spark-2.2.0-bin-hadoop2.7\hadoop\conf"
-Xmx1g org.apache.spark.deploy.SparkSubmit --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver spark-internal
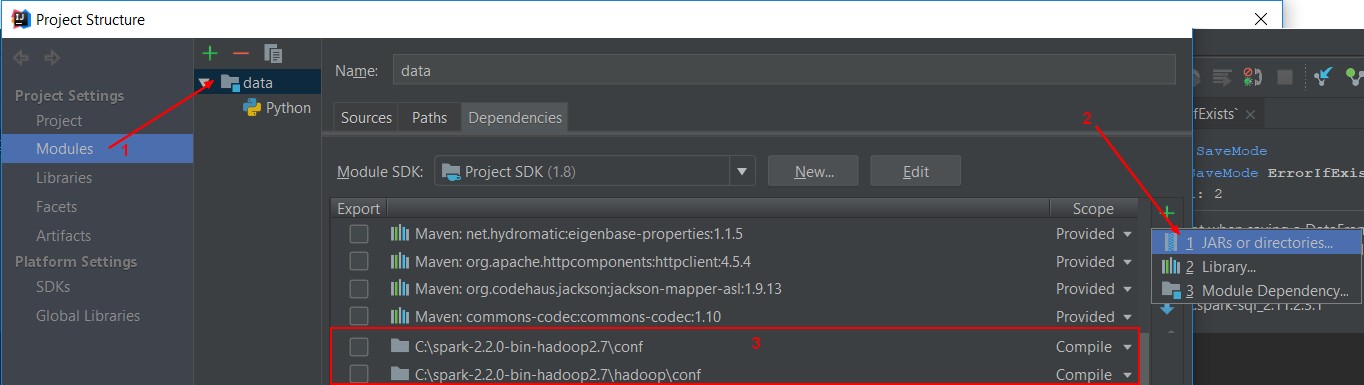
In your IDE, be sure to add this two directory in your classpath.
Example with IDEA:
Winutil
For windows only:
- Download and put winutils under the %HADOOP_HOME%\bin
Hive
In %HADOOP_HOME%\conf\hive-site.xml
Example of configuration file for a test environment where the base dir for hive is C:\spark-2.2.0-hive\
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>C:\spark-2.2.0-hive\scratchdir</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>C:\spark-2.2.0-hive\spark-warehouse</value>
<description>Spark Warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:c:/spark-2.2.0-metastore/metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
</configuration>
Directory
The hive configuration has two importants directory that must be writable:
- the scratch dir. A temporary runtime directory (default value is c:\tmp\hive, common location %TEMP%\hive)
- the warehouse. A directory where the internal Hive data are saved.
Steps:
- Make the directories
set SPARK-SCRATCHDIR=C:\spark-2.2.0-hive\scratchdir
set SPARK-WAREHOUSE=C:\spark-2.2.0-hive\warehouse
mkdir %SPARK-SCRATCHDIR%
mkdir %SPARK-WAREHOUSE%
- Hadoop - Winutils to set up the correct permissions.
winutils.exe chmod -R 777 %SPARK-SCRATCHDIR%
winutils.exe chmod -R 777 %SPARK-WAREHOUSE%
Metastore
The metastore is a Derby local metastore because the jar is already located in SPARK_HOME/jars
If when starting, you can see an error saying that it can found a driver, this is caused by a faulty Jdbc Url. Verify your URL
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:c:/spark-2.2.0-metastore/metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
You may install and configure locally a SQL Server if you want to access the metastore while Spark is running. Because the default Derby installation allows only one connection to the database
Sparklyr
sparklyr has a function to install a local spark instance.
- Install a local Spark.
# check the available version
spark_available_versions()
# Install the one that you want locally
spark_install(version = "1.6.2")
Installing Spark 1.6.2 for Hadoop 2.6 or later.
Downloading from:
- 'https://d3kbcqa49mib13.cloudfront.net/spark-1.6.2-bin-hadoop2.6.tgz'
Installing to:
- 'C:\Users\gerardn\AppData\Local\rstudio\spark\Cache/spark-1.6.2-bin-hadoop2.6'
trying URL 'https://d3kbcqa49mib13.cloudfront.net/spark-1.6.2-bin-hadoop2.6.tgz'
Content type 'application/x-tar' length 278057117 bytes (265.2 MB)
downloaded 265.2 MB
Installation complete.
- Restart RStudio and verify that you have the HADOOP_HOME
Sys.getenv("HADOOP_HOME")
[1] "C:\\Users\\gerardn\\AppData\\Local\\rstudio\\spark\\Cache\\spark-1.6.2-bin-hadoop2.6\\tmp\\hadoop"