
About
JDBC/ODBC means the Hive Server

where:
URL
jdbc:hive2://localhost:10000/default
Example
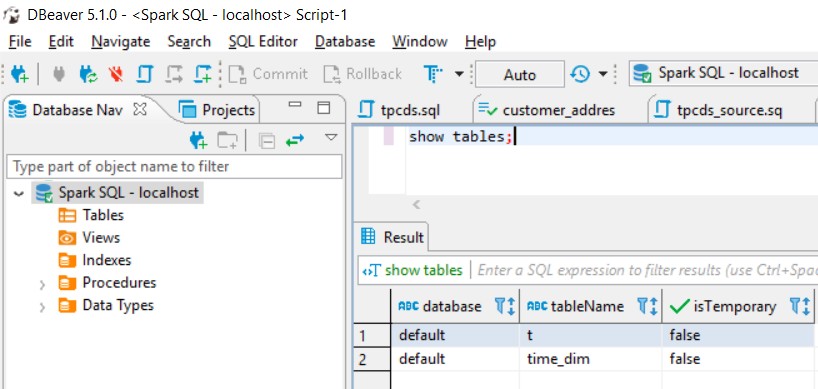
With dbeaver:
Artifacts
You need the core/common and the hive-jdbc jar.
Example for 1.2.1:
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.spark-project.hive/hive-jdbc
Moved to https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.2</version>
</dependency>