Data Mining - (Anomaly|outlier) Detection
About
The goal of anomaly detection is to identify unusual or suspicious cases based on deviation from the norm within data that is seemingly homogeneous.
Anomaly detection is an important tool:
The model trains on data that is homogeneous, that is all cases are in one class, then determines if a new case is similar to the cases observed, or is somehow “abnormal” or “suspicious”.
Data scientists realize that their best days coincide with discovery of truly odd features in the data.
This article try to talk about the detection of repeated anomaly or outliers and not over a rare event
Outliers vs Anomaly
An outlier is a legitimate data point originated from a real observation whereas an anomaly is illegitimate and produce by an artificial process.
Example
Anomaly detection is used mainly for detecting:
- fraud,
- (network) intrusion,
- and other rare events that may have great significance but are hard to find.
Anomaly detection can be used to solve problems like the following:
- A law enforcement agency compiles data about illegal activities, but nothing about legitimate activities. How can suspicious activity be flagged? The law enforcement data is all of one class. There are no counter-examples.
- Insurance Risk Modeling (e.g. Pednault, Rosen, Apte ’00) An insurance agency processes millions of insurance claims, knowing that a very small number are fraudulent. How can the fraudulent claims be identified? The claims data contains very few counter-examples. They are outliers. Claims are rare but very costly
- Targeted Marketing (e.g. Zadrozny, Elkan ’01). Given demographic data about a set of customers, identify customer purchasing behaviour that is significantly different from the norm. Response is typically rare but can be profitable
- Health care fraud, expense report fraud, and tax compliance.
- Web mining (Less than 3% of all people visiting Amazon.com make a purchase)
- Hardware Fault Detection (e.g. Apte, Weiss, Grout 93)
- Disease detection
- Network intrusion detection. Number of intrusions on the network is typically a very small fraction of the total network traffic
- Credit card fraud detection. Millions of regular transactions are stored, while only a very small percentage corresponds to fraud
- Medical diagnostics. When classifying the pixels in mammogram images, cancerous pixels represent only a very small fraction of the entire image
Method
To detect anomalies, they're two axis of analysis:
- the aggregation of a variable (vertical). An histogram for instance.
- the dimension of a data set (horizontal)
Unsupervised
- Deviation detection, outlier analysis, anomaly detection, exception mining
- Analyze each event to determine how similar (or dissimilar) it is to the majority, and their success depends on the choice of similarity measures, dimension weighting
- Clustering can also be used for anomaly detection. Once the data has been segmented into clusters, you might find that some cases do not fit well into any clusters. These cases are anomalies or outliers.
Supervised
The reason you are unlikely to get good results using classification or regression methods is that these methods typically depend on predicting the conditional mean of the data, and extreme events are usually caused by the conjunction of “random” factors all aligning in the same direction, so they are in the tails of the distribution of plausible outcomes, which are usually a long way from the conditional mean. Therefore, the approach that try to reformulate the problem into a normal learning problem loses important information.
Learning in order to solve rare event detection is similar to learn in a noisy environment
Single-Class Data
In single-class data, all the cases have the same classification.
Counter-examples, instances of another class, may be hard to specify or expensive to collect.
For instance, in text document classification, it may be easy to classify a document under a given topic.
However, the universe of documents outside of this topic may be very large and diverse. Thus it may not be feasible to specify other types of documents as counter-examples.
Anomaly detection could be used to find unusual instances of a particular type of document.
One-Class
Anomaly detection is a form of classification.
Anomaly detection is implemented as one-class classification, because only one class is represented in the training data.
An atypical data point can be either:
- an outlier
- or an example of a previously unseen class.
As opposite to a classification mode, a one-class classifier can't be trained on data that includes both examples, and counter-examples to distinguish between them. It develops then a profile to describes a typical case in the training data.
Deviation from the profile is identified as an anomaly.
One-class classifiers are sometimes referred to as positive security models, because they seek to identify “good” behaviours and assume that all other behaviours are bad.
The 11g ODM has a One Class Support Vector Machine.
Why not a Classification model
Solving a one-class classification problem can be difficult. The accuracy of one-class classifiers cannot usually match the accuracy of standard classifiers built with meaningful counterexamples.
The goal of anomaly detection is to provide some useful information where no information was previously attainable. However, if there are enough of the “rare” cases so that stratified sampling could produce a training set with enough counterexamples for a standard classification model, then that would generally be a better solution.
Extreme value theory
Extreme value theory or extreme value analysis (EVA) is a branch of statistics dealing with the extreme deviations from the median of probability distributions.
See : wiki/Extreme_value_theory
Aggregate Visualization
Aggregate Visualization is still the best way to spot anomalies because normally a single anomalous observation still stay in the norm.
Example: voter turnout vs the percentage of votes that went to the winner in several countries (from Statistical detection of systematic election irregularities)
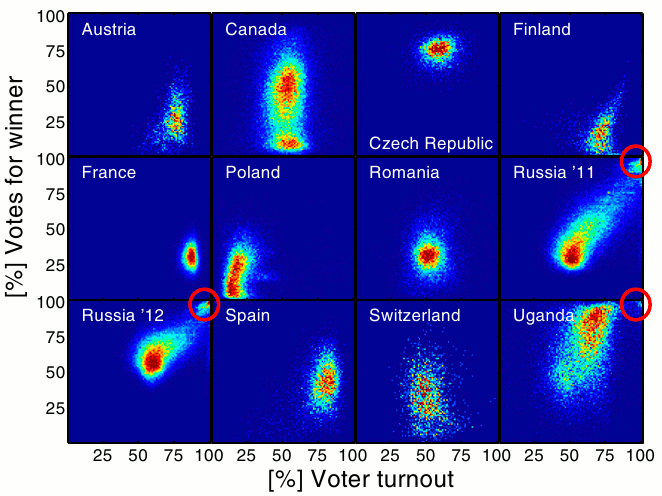
Dimension
The detection is made by finding records whose collection of attributes are in some way different than other records. It usually takes domain knowledge to discern between outliers and anomalies
- Mahalanobis Distance
- CADE
- Local Outlier factor
- k-mean. The data that are not assigned to any clusters are taken as outliers.
Accuracy
Accuracy is not appropriate for evaluating methods for rare event detection
Accuracy is not sufficient metric for evaluation
Example: network traffic data set with 99.9% of normal data and 0.1% of intrusions. A trivial classifier that labels everything with the normal class can achieve 99.9% accuracy.
Standard measures for evaluating rare class problems:
- Detection rate (Recall) - ratio between the number of correctly detected rare events and the total number of rare events
- False alarm (false positive) rate – ratio between the number of data records from majority class that are misclassified as rare events and the total number of data records from majority class
- ROC Curve is a trade-off between detection rate and false alarm rate
Calculation
Function
An unsupervised function that identifies items (outliers) that do not satisfy the characteristics of “normal” data.
It's implemented through one-class classification.
Anomalie detection although unsupervised, is typically used to predict whether a data point is typical among a set of cases.
An anomaly detection model predicts whether a data point is typical for a given distribution or not.
Algorithm
Oracle Data Mining supports One-Class Support Vector Machine (SVM) for anomaly detection. When used for anomaly detection, SVM classification does not use a target.