ODI - Setting up Journalizing/CDC
Introduction
This is the basic process for setting up CDC on an Oracle Data Integrator data model. Each of these steps is described in more detail below.
- Set the CDC parameters
- Add the datastores to the CDC
- For consistent set journalizing, arrange the datastores in order
- Add subscribers
- Start the journals
Articles Related
Steps
Import the JKM Knowledge module
A lot of different journalizing knowledge module are delivered with the standard installation of ODI. You must import one in the project in order to use it.

Set the data model CDC parameters
Edit the data model you want to journalize, and then select the Journalizing tab.
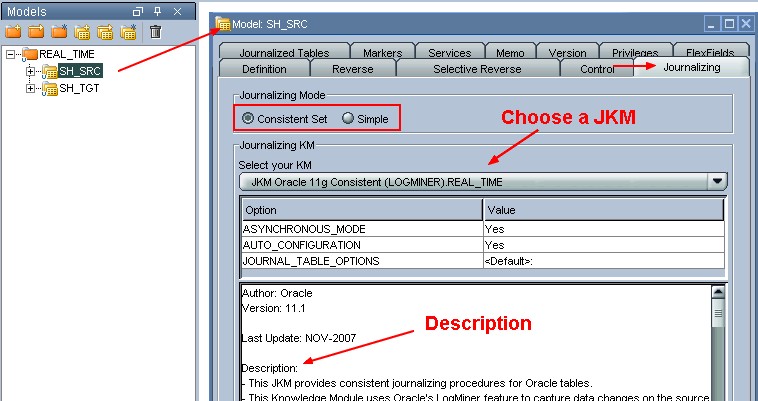
User configuration
Depending of the JKM that you choose, you have extra user configuration steps to perform. To have them, you must read the description part of the JKM.
Connect User
create/configure the user for AUTO_CONFIGURATION and ASYNCHRONOUS_MODE:
- to change instance parameters and to create objects
- to give the admin privileges for Oracle Streams (asynchronous mode only)
create user ODI identified by ODI;
-- Allow the user to grant system privileges to other users, to change instance parameters and to create objects
grant dba to ODI;
-- Grant the user with administrator privileges for Oracle Streams (asynchronous mode only)
BEGIN
DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE(GRANTEE => 'ODI');
END;
Work schema user
The work schema must be granted the SELECT ANY TABLE privilege be able to create views referring to tables stored in other schemas.
grant SELECT ANY TABLE to ODI;
Add or remove datastores to or from the CDC
You should now flag the datastores that you want to journalize. A change in the datastore flag is taken into account the next time the journals are (re)started.
When flagging a model or a sub-model (tables), all of the datastores contained in the model or sub-model (tables) are flagged.
- Select the datastore, the model or the sub-model you want to add/remove to/from CDC.
- Right-click then select Changed Data Capture > Add to CDC to add the datastore, model or sub-model to CDC, or select Changed Data Capture > Remove from CDC to remove it.
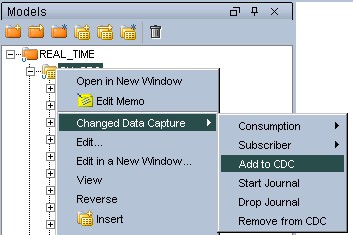
- Refresh the tree view. The datastores added to CDC should now have a marker icon. The journal icon represents a small clock. It should be yellow, indicating that the journal infrastructure is not yet in place.
![]()
It is possible to add datastores to the CDC after the journal creation phase. In this case, the journals should be re-started.
If a datastore with journals running is removed from the CDC in simple mode, the journals should be stopped for this individual datastore. If a datastore is removed from CDC in Consistent Set mode, the journals should be restarted for the model (Journalizing information is preserved for the other datastores).
Arrange the datastores in order (consistent set journalizing only)
You only need to arrange the datastores in order when using consistent set journalizing.
You should arrange the datastores in the consistent set into an order which preserves referential integrity when using their changed data.
For example, if an ORDER table has references imported from an ORDER_LINE datastore (i.e. ORDER_LINE has a foreign key constraint that references ORDER), and both are added to the CDC, the ORDER datastore should come before ORDER_LINE. If the PRODUCT datastore has references imported from both ORDER and ORDER_LINE (i.e. both ORDER and ORDER_LINE have foreign key constraints to the ORDER table), its order should be lower still.
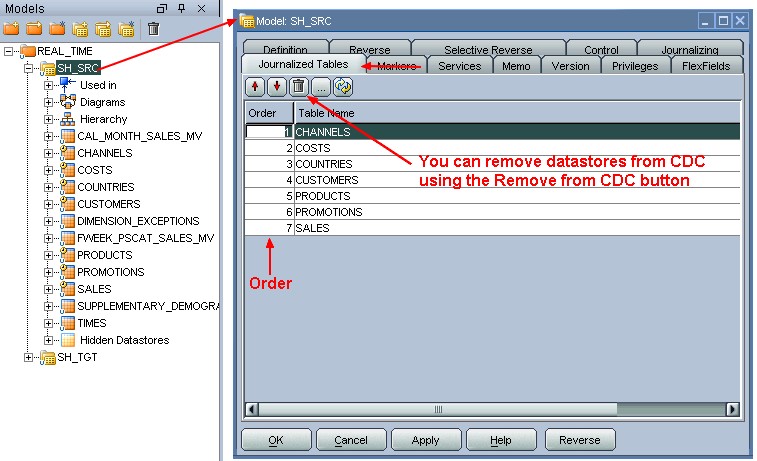
Changes to the order of datastores are taken into account the next time the journals are (re)started.
If existing scenarios consume changes from this CDC set, you should regenerate them to take into account the new organization of the CDC set.
Add or remove subscribers
When you add a subscriber for the first time, the Archive Log Mode of the database is verified on the step 25. This will be checked only the first time the journal is created. Afterwards, this statement is ignored thanks to the source query.

You must perform this action: Oracle Database - How to change the Database Archiving Mode
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
ALTER SYSTEM ARCHIVE LOG START;
To verify that archive logging is properly configured, perform:
ALTER SYSTEM SWITCH LOGFILE;
and verify that a new archive log file has been created in the archive log directory. Do not continue, until this works.

Start/stop the journals
Starting the journals creates the CDC infrastructure if it does not exist yet. It also validates the addition, removal and order changes for journalized datastores.
Stopping the journals deletes the entire the journalizing infrastructure and all captured changes are lost. Restarting a journal does not remove or alter any changed data that has already been captured.
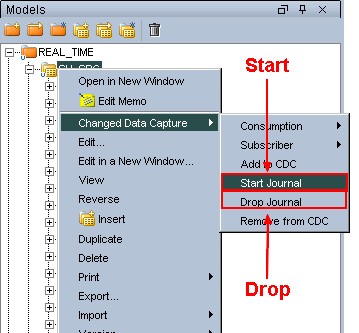
A session begins to start or drops the journals. You can track this session from the Operator. The journalizing status of the table must become green.
Verification of the journalizing Status

Datastores in models or interfaces have an icon marker indicating their journalizing status in Designer's current context:
- OK - Journalizing is active for this datastore in the current context, and the infrastructure is operational for this datastore.
- No Infrastructure - Journalizing is marked as active in the model, but no appropriate journalizing infrastructure was detected in the current context. Journals should be started. This state may occur if the journalizing mode implemented in the infrastructure does not match the one declared for the model.
- Remnants - Journalizing is marked as inactive in the model, but remnants of the journalizing infrastructure such as the journalizing table have been detected for this datastore in the context. This state may occur if the journals were not stopped and the table has been removed from CDC.
See Changed Data with the Journal Data
Once journalizing is started and changes are tracked for subscribers, it is possible to view the changes captured.
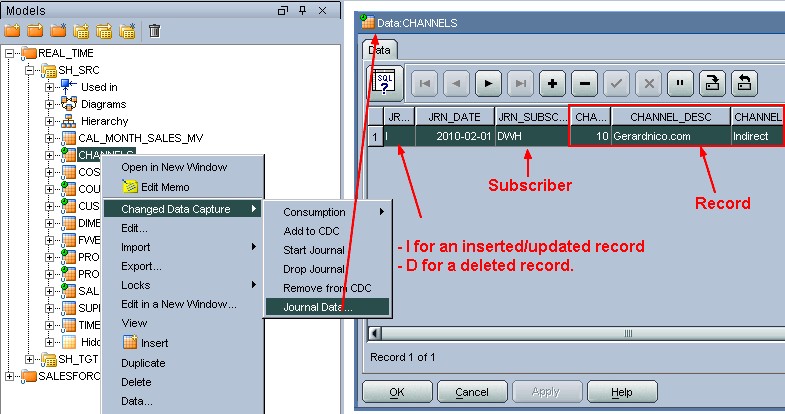
This window selects data using the journalizing views.
The changed data displays three extra columns for the changes details:
- JRN_FLAG: Flag indicating the type of change. It takes the value I for an inserted/updated record and D for a deleted record.
- JRN_SUBSCRIBER: Name of the Subscriber.
- JRN_DATE: Timestamp of the change.
Journalized data is mostly used within integration processes. Changed data can be used as the source of integration interfaces. The way it is used depends on the journalizing mode.
Package to automate the Subscribers and Start Journals operations
The journalizing infrastructure is implemented by the journalizing KM at the physical level. Consequently, Add Subscribers and Start Journals operations should be performed in each context where journalizing is required for the data model. It is possible to automate these operations using Oracle Data Integrator packages. Automating these operations is recommended to deploy a journalized infrastructure across different contexts.
Typical situation: the developer manually configures CDC in the Development context. After this is working well, CDC is automatically deployed in the Test context by using a package. Eventually the same package is used to deploy CDC in the Production context.
To automate journalizing setup:
- Double-Click the step icon in the diagram. The properties panel opens.
- In the Type list, select Journalizing Model/Datastore.
- Check the Start box to start the journals.
- Check the Add Subscribers box, then enter the list of subscribers into the Subscribers group.
- Click OK to save.
- Generate a scenario for this package.
When this scenario is executed in a context, it starts the journals according to the model configuration and creates the specified subscribers using this context.
It is possible to split subscriber and journal management into different steps and packages. Deleting subscribers and stopping journals can be automated in the same manner.
Support
STREAM POOL SIZE
ALTER SYSTEM SET STREAMS_POOL_SIZE=52428800 SCOPE=BOTH;
Primary Key
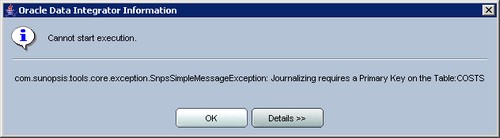
alter table "SALES" add constraint SALES_PK primary key("PROD_ID","CUST_ID","TIME_ID","CHANNEL_ID","PROMO_ID")