About
Cassandra is a NoSql database for transactional workloads that require high scale and maximum availability.
Cassandra is suited for transactional workloads at high volume and shouldn’t be considered as a data warehouse
Model
Query First Design
You don’t start with the data model; you start with the query model.
It is designed to work on a denormalized data model.
Data is arranged as one query per table, and data is repeated amongst many tables, a process known as denormalization.
A table is designed to satisfy a query that should support a process (user registration, user login, …)
Joins are not supported,
- they are performed client side
- (preferred) or a second table was created to represent with the join results
Performing joins on the client should be a very rare case; you really want to duplicate (denormalize) the data instead.
There is no concept of foreign keys or relational integrity.
In contrario, a relational database’s approach to data modeling is table-centric.
Materialized views are available (since 3.0) allows to create multiple denormalized views of data and keeps it in sync with the table
A key goal is to minimize the number of partitions that must be scanned in order to satisfy a query. Because the partition is a unit of storage that does not get divided across nodes, a query that searches a single partition will typically yield the best performance
Sorting
The sort order available on queries is fixed, and is determined entirely by the selection of clustering columns you supply in the CREATE TABLE command.
The CQL SELECT statement does support ORDER BY semantics, but only in the order specified by the clustering columns (ascending or descending).
Procedure
The user interface design for the application is often a great artifact to use to begin identifying queries
You create a logical model containing a table for each query, capturing entities and relationships from the conceptual model
To name each table, identify the primary entity type for which you are querying, and use that to start the entity name. If you are querying by attributes of other related entities, you append those to the table name, separated with _by_; for example, hotels_by_poi.
Next, identify the primary key for the table with:
- the partition key columns based on the required query attributes,
- and the clustering columns in order to guarantee uniqueness and support desired sort ordering
If any of the other additional attributes are the same for every instance of the partition key, mark the column as static. For instance, if a name is in the partition key, you could had a description attribute as static column.
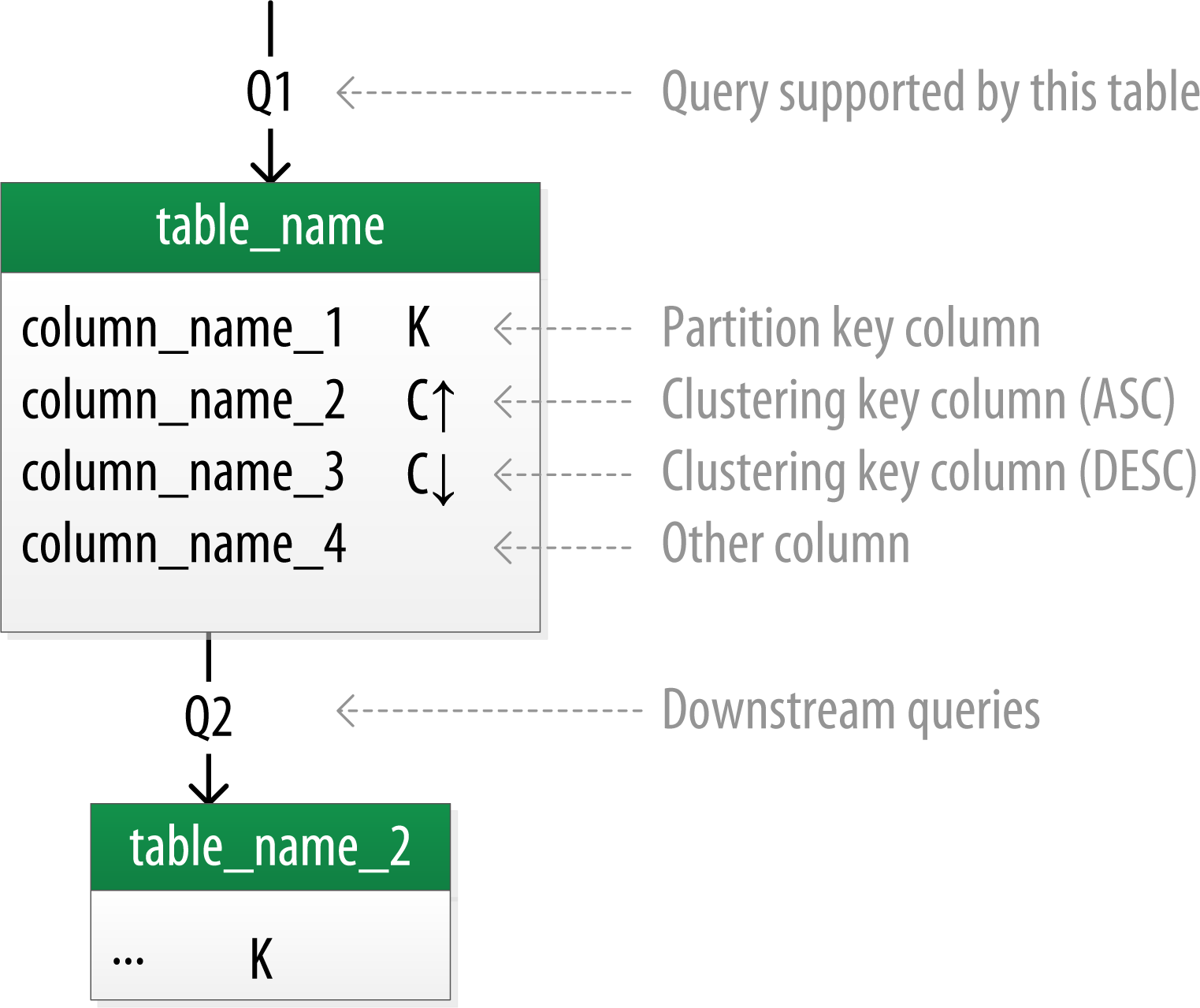
Artem Chebotko Diagram helps visualize the relationships between queries and tables:
- Each table is shown with its title and a list of columns.
- Primary key columns are identified via symbols such as K for partition key columns and C↑ or C↓ to represent clustering columns.
- Lines are shown entering tables or between tables to indicate the queries that each table is designed to support
If you’re searching by attribute, this attribute should be a part of the primary key.
KKV store
It's not a KV store (key value) but a KKV store 2)
- First Key is the partition key (the partition identifier mades up of the node and the partition file) - this key should be almost used in all query.
- Second Key is the clustering key (the row identifier inside the partition - sorting key) - this key should be chronological (ie a surrogate key that can be sorted by time).
- V: value
Example:
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
where:
- channel_id, bucket is the partition key
- message_id is the clustering key
Data Structure
- Keyspace: defines how a dataset is replicated, for example in which datacenters and how many copies. Keyspaces contain tables.
- Table: defines the typed schema for a collection of partitions. Cassandra tables have flexible addition of new columns to tables with zero downtime. Tables contain partitions, which contain partitions, which contain columns.
- Partition: defines the mandatory part of the primary key all rows in Cassandra must have. All performant queries supply the partition key in the query.
- Row: contains a collection of columns identified by a unique primary key made up of the partition key and optionally additional clustering keys.
- Column: A single datum with a type which belong to a row.
Primary key
PRIMARY KEY (
(partitionCol1, ..., partitionColN),
clusteringCol1, ..., clusteringColN
)
- the columns combination define the uniqueness of the record in the database.
- partitionCol1, …, partitionColN defines the partition that define the data localization inside the cluster (known as data locality). When data is inserted into the cluster, the first step is to apply a hash function that generate the partition key. This key is used to determine what node (and replicas) will get the data. The goal is to distribute the data evenly.
- clusteringCol1, …, clusteringColN are clustering columns that specifies the default order inside a partition (ie the default order returned by a query). The CLUSTERING ORDER BY clause can be used to specify it with directionality (ASC, DESC) in a CREATE table statement. Clustering order is a pre-sorting feature.
Time Serie
Cassandra has support for modelling time series data wherein each row can have dynamic number of columns.
When CLUSTERING ORDER BY is used in time series data models, As an example:
- with the following CLUSTERING ORDER BY
PRIMARY KEY (userid, added_date, videoid)
- we can quickly access the last N items inserted.
SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 LIMIT 10;
Installation
Database
docker run ^
--name cassandra ^
-d ^
cassandra:3.11.5
- then
docker exec -it cassandra bash
- and Cqlsh
cqlsh localhost
- Query
SELECT cluster_name, listen_address FROM system.local;
cluster_name | listen_address
--------------+----------------
Test Cluster | 172.17.0.3
- Create a keyspace (A keyspace is the cassandra name for a SQL schema) - default, schema are built-in words that cannot be used otherwise you get: SyntaxException: line 1:16 no viable alternative at input 'schema' (create keyspace [schema]…)
create keyspace mySchema with replication = {'class':'SimpleStrategy','replication_factor':1};
use mySchema;
CREATE TABLE t (
pk int,
t int,
v text,
s text static,
PRIMARY KEY (pk, t)
);
INSERT INTO t (pk, t, v, s) VALUES (0, 0, 'val0', 'static0');
INSERT INTO t (pk, t, v, s) VALUES (0, 1, 'val1', 'static1');
SELECT * FROM t;
pk | t | s | v
----+---+---------+------
0 | 0 | static1 | val0
0 | 1 | static1 | val1