
Algorithm - Asymptotic Analysis
About
Asymptotic analysis provides basic vocabulary for discussing the design and analysis in algorithms. This is the language by which every serious computer programmer and computer scientist discusses the high level performance of computer algorithms.
High-level idea: Suppress constant factors and lower-order terms with a focus on the case of a large input sizes.
Asymptotic analysis is a formalism which essentially by definition suppresses:
- constant factors
- and lower-order terms.
The performance of an algorithm as the size N of the input grows large, that is, tends to infinity.
It's a algorithm guiding principle because only large input sizes are interesting. If 100 numbers need to be sorted, whatever method can be used and it's gonna happen instantaneously on modern computers.
Thinking about high-level algorithmic approaches, when you want to make a comparison between fundamentally different ways of solving a problem. Asymptotic Analysis is often the right tool for giving a guidance about which one is going to perform better, especially on reasonably large inputs.
constant factors are hugely important in practice, for crucial programs but understanding tiny constant factors in the analysis is an inappropriate level of granularity for asymptotic analysis.
but once you've committed to a particular algorithmic solution to a problem. Of course, you might want to then work harder to improve the leading constant factor, perhaps even to improve the lower order terms.
Articles Related
Moore's Law
Moore's Law, with computers getting faster, actually says that our computational ambitions will naturally grow. We naturally focus on ever larger problem sizes. And the gulf between an <math>n^2</math> algorithm and an <math>n.log_2(n)</math> algorithm will become ever wider.
By using an algorithm with a running time which is proportional:
- to the input size, the computers get faster by a factor of four and only problems with a factor of four or larger can then be solved.
- to the square of the input size, the computer gets faster by a factor of four and only problem with a factor of two in size can be solved.
Small constant factors and lower-order terms suppression
Asymptotic Analysis is much more concerned with the rate of growth on an algorithms performance than on things like:
- low-order terms: irrelevant for large inputs
- or on small changes in the constant factors: too system-dependent
Asymptotic Analysis suppress all of the details that you want to ignore. On the other hand, it's sharp enough to be useful. In particular, to make predictive comparisons between different high level algorithmic approaches on large input to solving a common problem.
Justifications:
- Mathematically easier and true for N Large
- Constants depend on architecture / compiler / programmer anyways
- Lose very little predictive power
Mathematically easier and true for N Large
It's way easier mathematically, if we don't have to worrying about small changes in:
- the constant factors
- or lower-order terms.
For instance on the merge sort, the merge subroutine running time <math>4n + 2</math> becomes <math>\approx 6n</math>
And we can argue that merge sort <math>6n log_2 n + 6n </math> is a better, faster algorithm than something like insertion sort <math>\frac{1}{2} n^2</math> , without actually discussing the constant factors at all.
This is a mathematical statement that is true if and only if N is sufficiently large.
| n=200 | n=1400 |
|---|---|
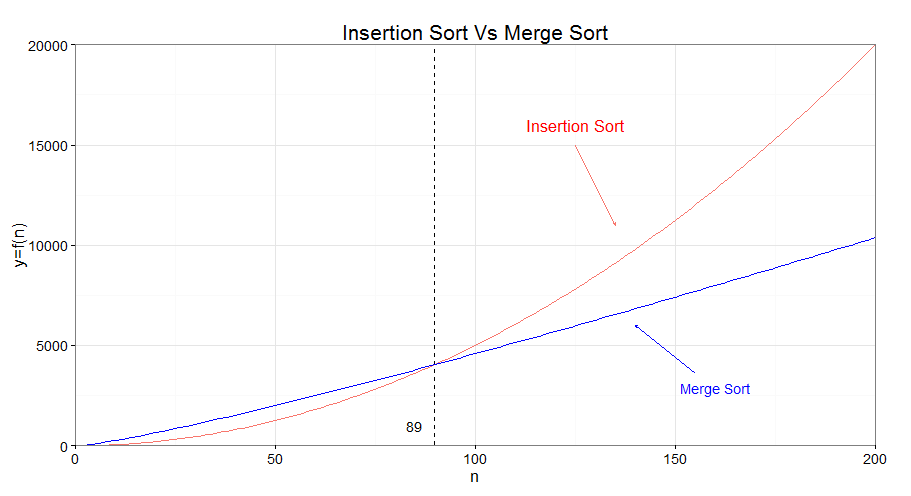 | 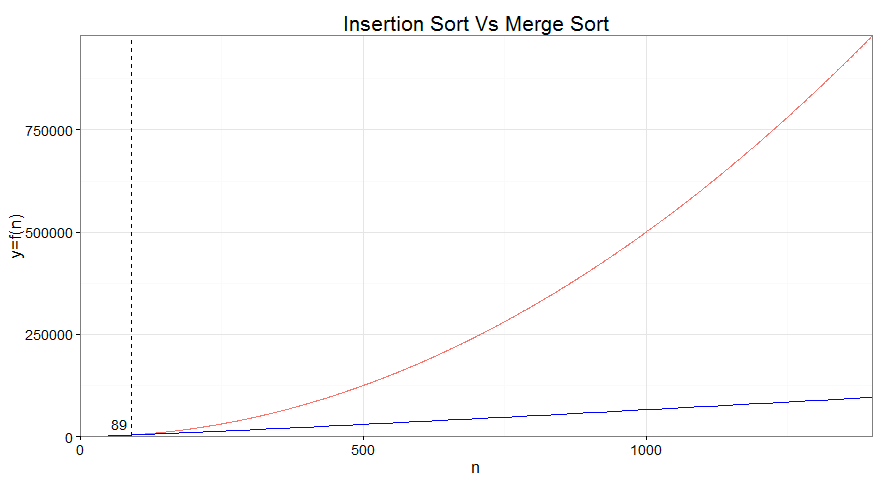 |
Implementation dependent
The number of lines of code and therefore the constants will deviate not but a lot but by small constant factors depending on:
- the programming implementation.
- ie how the pseudo code gets translated into the program language (like C, Java)
- ie who the programmer is
- the compiler and its optimizations.
- ie how the program is compiled down into machine code.
- ie what the compiler is
- the exact processor,
- and so on.
Lose very little predictive power
Because algorithms are described at a level, that transcends any particular programming language, it would be inappropriate to specify precise constants.
By suppressing the constant factor, we lose a little bit of granularity of information. But we don't lose in what we really care about, which is accurate guidance about what algorithms are gonna be faster than others.
Notation
Vocabulary for the design and analysis of algorithms. See big-Oh notation)
Formal definition
T(n) is big-Oh of f(n) means that for all sufficiently large values of n, T(n) is bounded above by a constant multiple <math>c</math> of <math>f(n)</math> .
<MATH> T(n) <= c.f(n) </MATH> where:
- f(n) is some basic function, like for example, <math>n</math> , <math>n^2</math> , <math>n log n</math> .
The formal definition is the way to prove that for all n at least n0, c times f(n) upper-bounds T(n).
Example:
- T(n) denoted by the blue functions
- f(n) is denoted by the green function which lies below T(n).
But when we double f(n), we get a function that eventually crosses T(n) and for-evermore is larger than it. In this case, T(n) is indeed a Big-Oh of f(n).
For all sufficiently large n, a constant (in this case twice) multiple times of f(n) is an upper bound of T(n).
In mathematics, T(n) is no more than c times f(n) for all n that exceed or equal n0.
The constants have the following role:
- c quantifies the constant multiple of f(n)
- and n0 quantifies sufficiently large. It's the threshold beyond which we insist that, c times f(n) is an upper-bound on T(n)
On the example,
- c is just going to be two.
- and n0 is the crossing point.
The best way to establish that a function is big-Oh of some function, is to play a game against an opponent where you want to prove the formal definition. The formal definition inequality holds and the opponent must show that it doesn't hold for sufficiently large n. You pick a strategy in the form of a constant c and a constant n0 and your opponent is then allowed to pick any number n larger than n0.
- The function is big-Oh of f(n) if you can up front commit to constants c and n0 so that no matter how big of an n your opponent picks, this inequality holds.
- The function is not big-Oh of f(n) if no matter what C and n0 you choose your opponent can always flip this in equality.