GPU - CUDA
About
CUDA is a application programming interface (API) created by Nvidia that allows software developers to use a CUDA-enabled graphics processing unit (GPU) for general purpose processing in parallel. ie CUDA gives direct access to the GPU's instruction set
CUDA provides both:
- a low level API (CUDA Driver API, non single-source)
- and a higher level API (CUDA Runtime API, single-source).
Articles Related
Windows installation
From Doc
Prerequisites
graphic card
- a supported NVIDIA graphic card
- Open device manager and check the Display Adapters
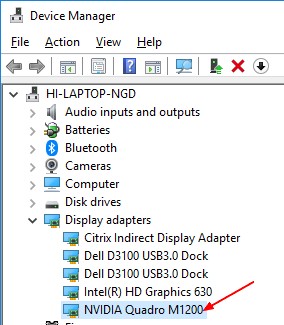
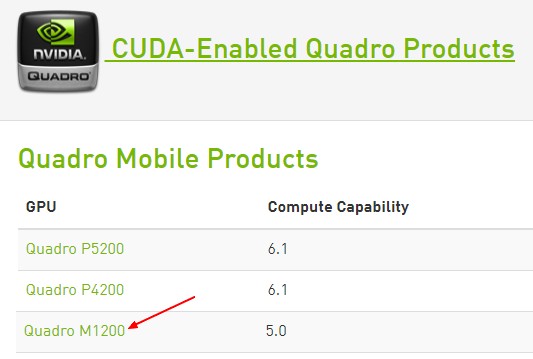
- Check that this display is listed in the CUDA enabled GPU
Microsoft Visual Studio
A supported version of Microsoft Visual Studio. See the installation page requirement for the list of supportED product. I have installed Community 2019. https://visualstudio.microsoft.com/
Installation
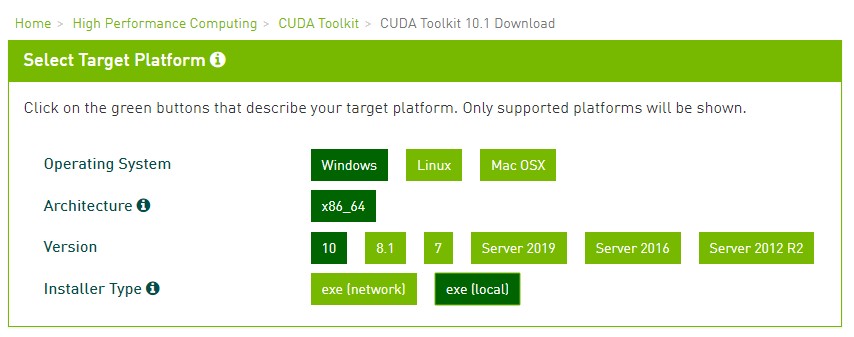
- Download the toolkit at https://developer.nvidia.com/cuda-downloads
fciv.exe -add cuda_10.1.105_418.96_win10.exe -md5
//
// File Checksum Integrity Verifier version 2.05.
//
25a060d492acbed7c549f65204e14e76 cuda_10.1.105_418.96_win10.exe
- Install
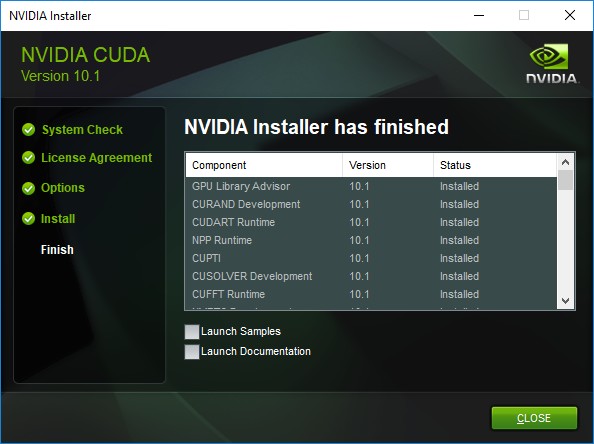
- The PATH environment variable was changed with the below path
%NVIDIA_HOME%\libnvvp;%NVIDIA_HOME%\bin
:: for my installation with home = C:\NvidiaGpuToolkit\CUDA\10.1
C:\NvidiaGpuToolkit\CUDA\10.1\libnvvp;C:\NvidiaGpuToolkit\CUDA\10.1\bin;
Verification
Version
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Fri_Feb__8_19:08:26_Pacific_Standard_Time_2019
Cuda compilation tools, release 10.1, V10.1.105
Build
- Create the env CUDA_PATH that points to the directory given in the Table 4. CUDA to the Visual Studio .props locations. For instance, C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\visual_studio_integration\MSBuildExtensions. You should find in it the file CUDA 10.1.props, If you don't do it, you got a problem with the loading of the proejct due to a bad $(CUDAPropsPath)
- When opening the solution file Samples_vs2017.sln at the root of the samples, it should take time to load.
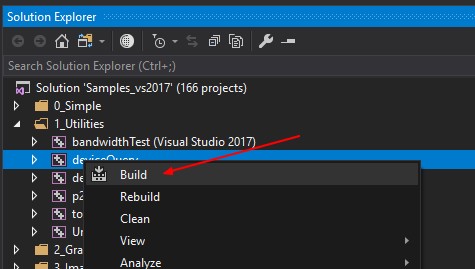
- Go to the deviceQuery Project
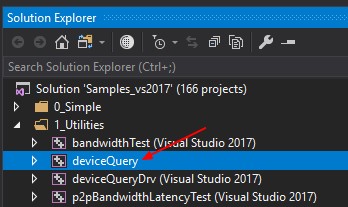
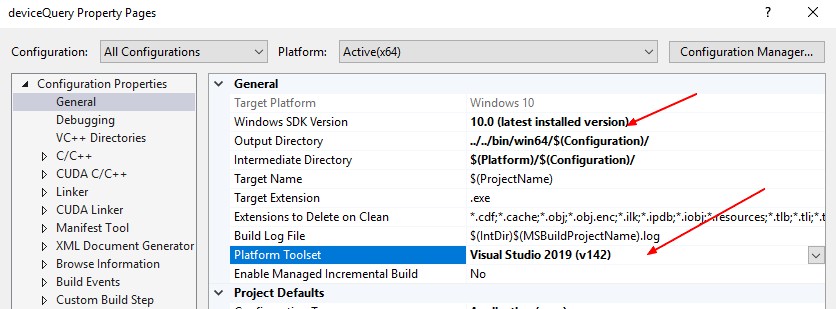
- Change the runtime tool set and the sdk if needed in the project properties (Right Click)
- Build
- Test the binary created. The important outcomes are that a device was found, that the device(s) match what is installed in your system, and that the test passed.
cd C:\NvidiaGpuToolkit\CUDA\Samples\10.1\bin\win64\Debug
deviceQuery.exe
C:\NvidiaGpuToolkit\CUDA\Samples\10.1\bin\win64\Debug\deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Quadro M1200"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 5.0
Total amount of global memory: 4096 MBytes (4294967296 bytes)
( 5) Multiprocessors, (128) CUDA Cores/MP: 640 CUDA Cores
GPU Max Clock rate: 1148 MHz (1.15 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 4 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 1
Result = PASS