Automata - Finite Automata
About
A finite automaton is an automaton that has a set of states and its control moves from state to state in response to external inputs.
It has a start and an end state and there are only a finite number of states
Articles Related
Definition
A formal de definition of a finite automaton is whenever:
- an input X is received by an automaton,
- the automaton must follow an arc labeled X from the state it is in to some new state (for all states)
Class
- deterministic: the automaton cannot be in more than one state at any one time
- nondeterministic: the automaton may be in several states at once
Example
Lexer
An automaton implementing a lexer modeling the recognition of the keyword then
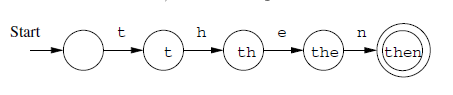
where:
- the state (circle) represents a different position in the word then that has been reached so far that ranges from:
- the empty string (ie nothing)
- to the complete word
Others
- Process - LifeCycle (Entity State) (Status) Software for verifying systems of all types that have a finite number of distinct states
- A finite automata model electronic circuits.
Implementation
The advantage of having only a finite number of states is that we can implement the system with a fixed set of resources
Example:
- Hardware: we could implement it in hardware as a circuit
- Software: to make the decision
- looking at the state
- or using the position in the code itself
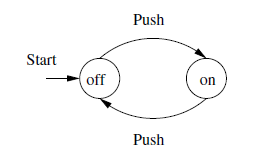
Model
example: A on/off button