About
Regular expression are Expressions that defines a pattern (ie structure) in text.
This is therefore a language that permits to define structure of a text.
They are a mathematically-defined concept, invented by Stephen Kleene in 1956. The original version defined expressions using:
- just literal characters,
The Glob language behave a lot like a regular expression but is not. The difference is mostly in the signification of the star and is use a lot in Shell in order to match file name. See Glob - Globbing (Wildcard expression).
Example
Simple Date Parsing
The below expression describes a date:
\d{4}-\d{2}-\d{2}
where:
- \d is a character class that means a digit (0 to 9)
- {4} is a quantifier that states that you expect 4 instance of the previous character or group
It permits to parse ISO 86021 string date such as
2022-07-28
Log Parsing
Java regular expression used to parse log message at Twitter circa 2010
^(\\w+\\s+\\d+\\s+\\d+:\\d+:\\d+)\\s+
([^@]+?)@(\\s+)\\s+(\\S+):\\s+(\\S+)\\s+(\\S+)
\\s+((?:\\S+?,\\s+)*(?:\\S+?))\\s+(\\S+)\\s+(\\S+)
\\s+\\[([^\\]]+)\\]\\s+\"(\\w+)\\s+([^\"\\\\]*
(?:\\\\.[^\"\\\\]*)*)\\s+(\\S+)\"\\s+(\\S+)\\s+
(\\S+)\\s+\"([^\"\\\\]*(?:\\\\.[^\"\\\\]*)*)
\"\\s+\"([^\"\\\\]*(?:\\\\.[^\"\\\\]*)*)\"\\s*
(\\d*-[\\d-]*)?\\s*(\\d+)?\\s*(\\d*\\.[\\d\\.]*)?
(\\s+[-\\w]+)?.*$
where:
- ^ is a boundary meta matching the beginning of a line.
- + is a quantifier quantifying the number of occurrences
- \ is the escape character
- \d is a shorthand character classes matching digits
- \w is a shorthand character classes matching word characters (letters, digits, and underscores)
- \s is a shorthand character classes matching whitespace (spaces, tabs, and line breaks)
Usage
Regular expressions are used in many systems.
Syntax
/regularExpression/modifier
where:
- a regular expression is a string that is composed of:
- that are quantified
- grouped (or not) to:
- capture (extract)
- or make assertions (assertion (look-around))
- through a logical way.
- flag also called modifier modifies the behavior of the parsing (such as if the match should take the case (upper,lower) into account,…)
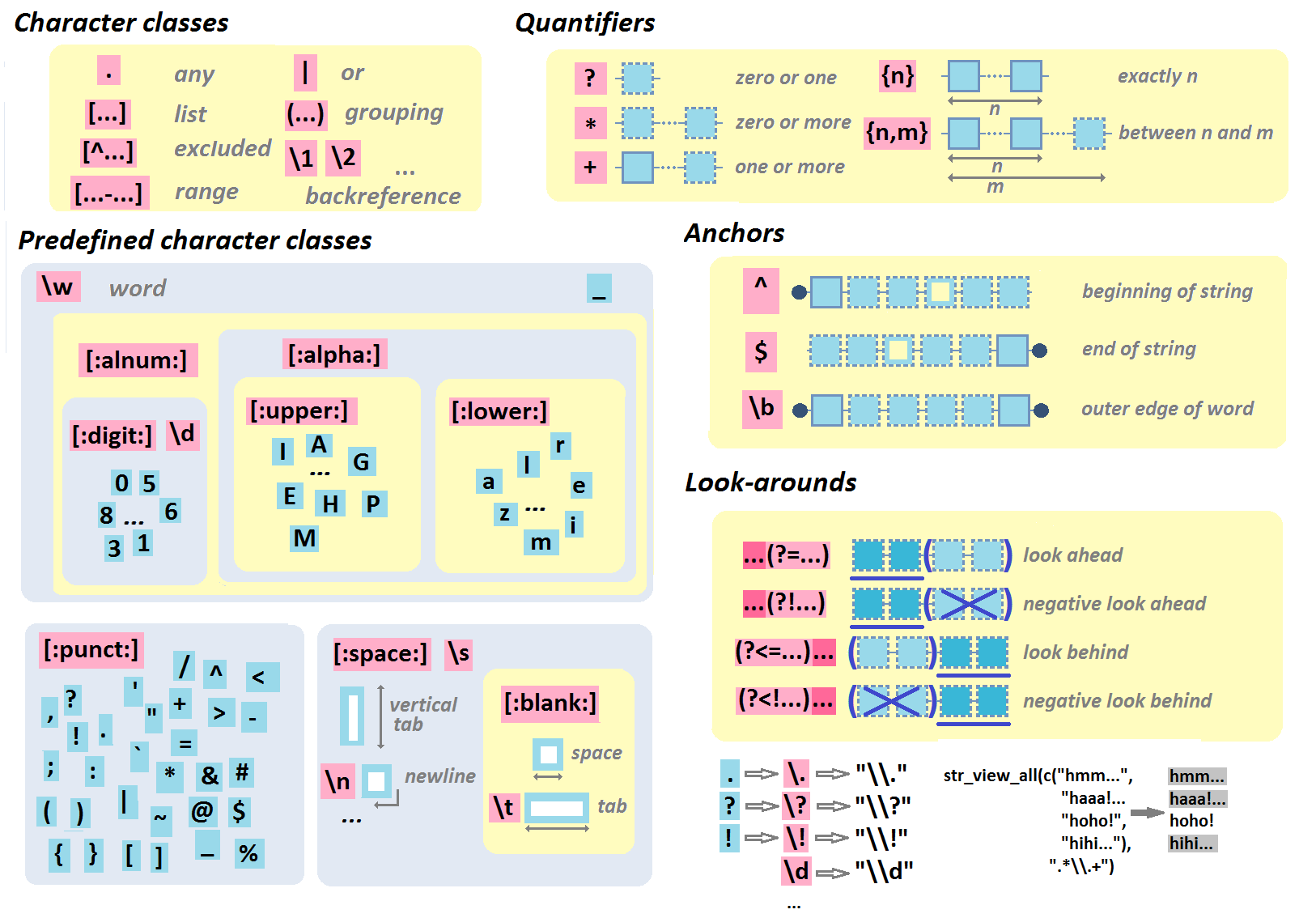
See meta to get an overview of the most important regexp (symbols|token) that have a meaning in the context of regular expression.
Regular language and Automata
Regular expressions are implemented with context-free grammars and are the building block of regular language.
Stephen Kleene was the fellow who invented regular expressions and showed that they describe the same languages that finite automata describe. Most regexp-packages transform a regular expression into an automaton based on nondeterministic automata (NFA). The automaton does then the parse work.
Regular expression can be matched against text using a Definite Finite Automaton (DFA). DFA's have the important property of running on arbitrary text of length n in O(n) time and using O(1) space. Presented with a regular expression and a candidate text, a DFA decides whether the text matches the expression.
Engine / Grammar
The syntax can differ from one implementation to an other but then tend to follow the same principal.
The most known implementation is PCRE that is followed by most of the language
Visualisation
Regular expression are visualized via rail road diagram.