About
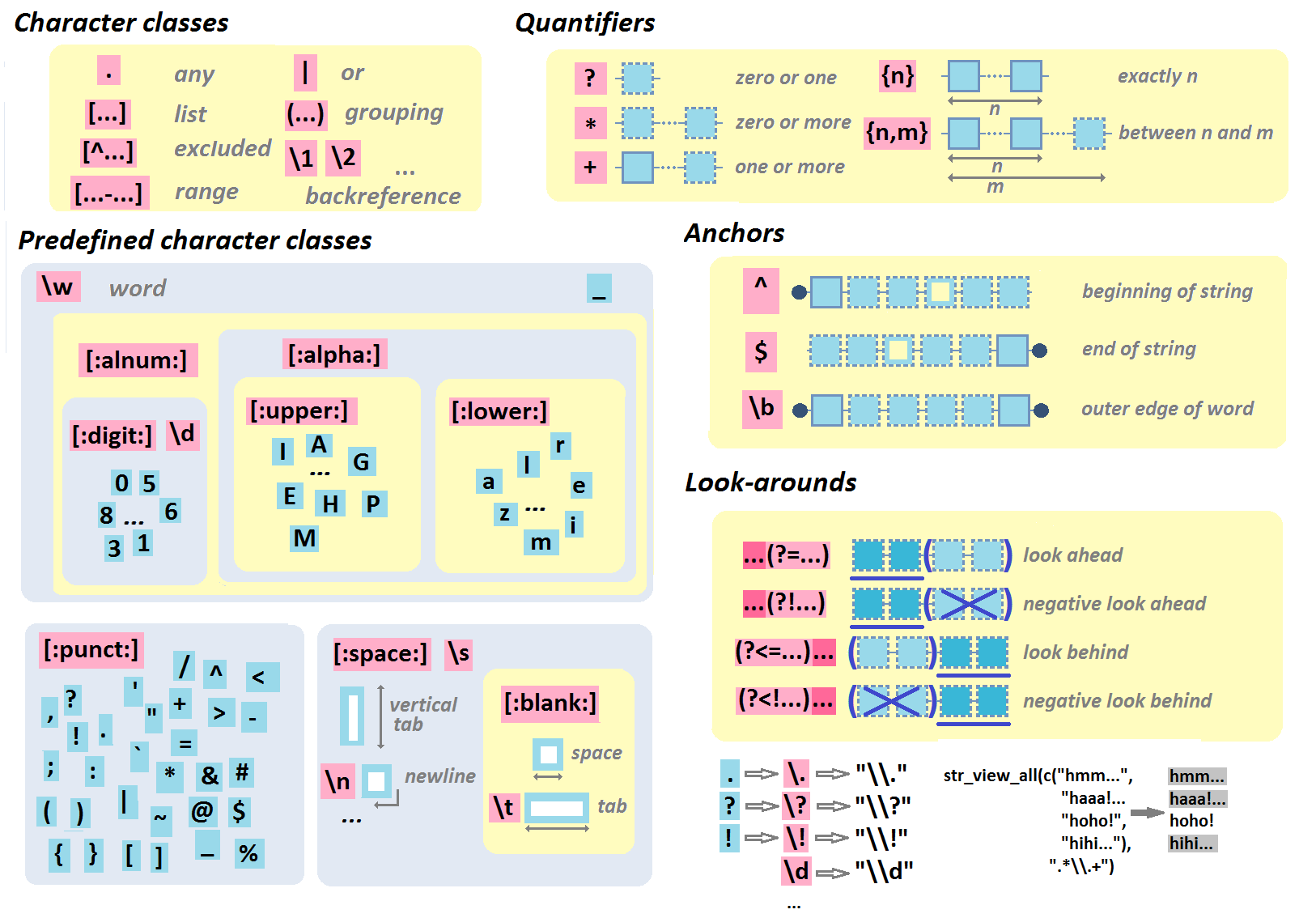
A character class defines a domain of permitted characters.
They may be also known as character set (in a regular expression)
Not to confound with the character set used to encode a text into bit but you can represent a whole character set with a character class.
For instance, if your regular expression engine supports it, you could represent all ASCII characters with
[:ASCII:]
Syntax
with square brackets
[]
where:
- [ is the start character class definition
- ] is the end character class definition
Inside the brackets, all characters can be used mixed with this Meta characters symbols
| Construct | Matches | Operation |
|---|---|---|
| [abc] | a, b, or c | simple class |
| [^abc] | Any character except a, b, or c | negation |
| [a-zA-Z] | a through z or A through Z, inclusive | range |
| [a-d[m-p]] | a through d, or m through p: [a-dm-p] | union |
| [a-z&&[def]] | d, e, or f | intersection |
| [a-z&&[^bc]] | a through z, except for b and c: [ad-z] | subtraction |
| [a-z&&[^m-p]] | a through z, and not m through p: [a-lq-z] | subtraction |
Other:
| [..] | Specifies one collation element, and can be a multicharacter element | [.ch.] in Spanish |
| [:characterClass:] | Specifies character classes. It matches any character within the character class. | [:alpha:] See posix |
| [==] | Specifies equivalence classes. | [=a=] matches all characters having base letter 'a'. |
Meta
| Meta-character | Description | Example |
|---|---|---|
| \ | general escape character | |
| ^ | negate the class, but only if the first character | [^abc] matches any character other than a, b, or c. [^a-z] matches any single character that is not a lowercase letter from a to z. |
| - | indicates character range | [abc] matches a, b, or c. [a-z] specifies a range which matches any lowercase letter from a to z. These forms can be mixed: [abcx-z] matches a, b, c, x, y, and z, as does [a-cx-z] |
Type
POSIX
Since many ranges of characters depend on the chosen locale setting (i.e., in some settings letters are organized as abc…zABC…Z, while in some others as aAbBcC…zZ), the POSIX standard defines some classes or categories of characters as shown in the following table:
| POSIX | ASCII | Description |
|---|---|---|
| [:alnum:] | [A-Za-z0-9] | Alphanumeric characters |
| [:alpha:] | [A-Za-z] | Alphabetic characters |
| [:lower:] | [a-z] | Lowercase letters |
| [:upper:] | [A-Z] | Uppercase letters |
| [:blank:] | [ \s\t] | Space and tab |
| [:cntrl:] | [\x00-\x1F\x7F] | Control characters |
| [:digit:] | [0-9] | Digits |
| [:graph:] | [\x21-\x7E] | Visible characters |
| [:print:] | [\x20-\x7E] | Visible characters and spaces |
| [:punct:] | [-!"#$%&'()*+,./:;<=>?@[\\\]_`{|}~] | Punctuation characters |
| [:space:] | [ \t\r\n\v\f] | Whitespace characters |
| [:xdigit:] | [A-Fa-f0-9] | Hexadecimal digits |
Unicode Set
By default, the Unicode set will show you
Shorthand
The shorthand syntax begins with a slash followed by a letter. See Regular Expression - Backslash Generic Character Class (shorthand)