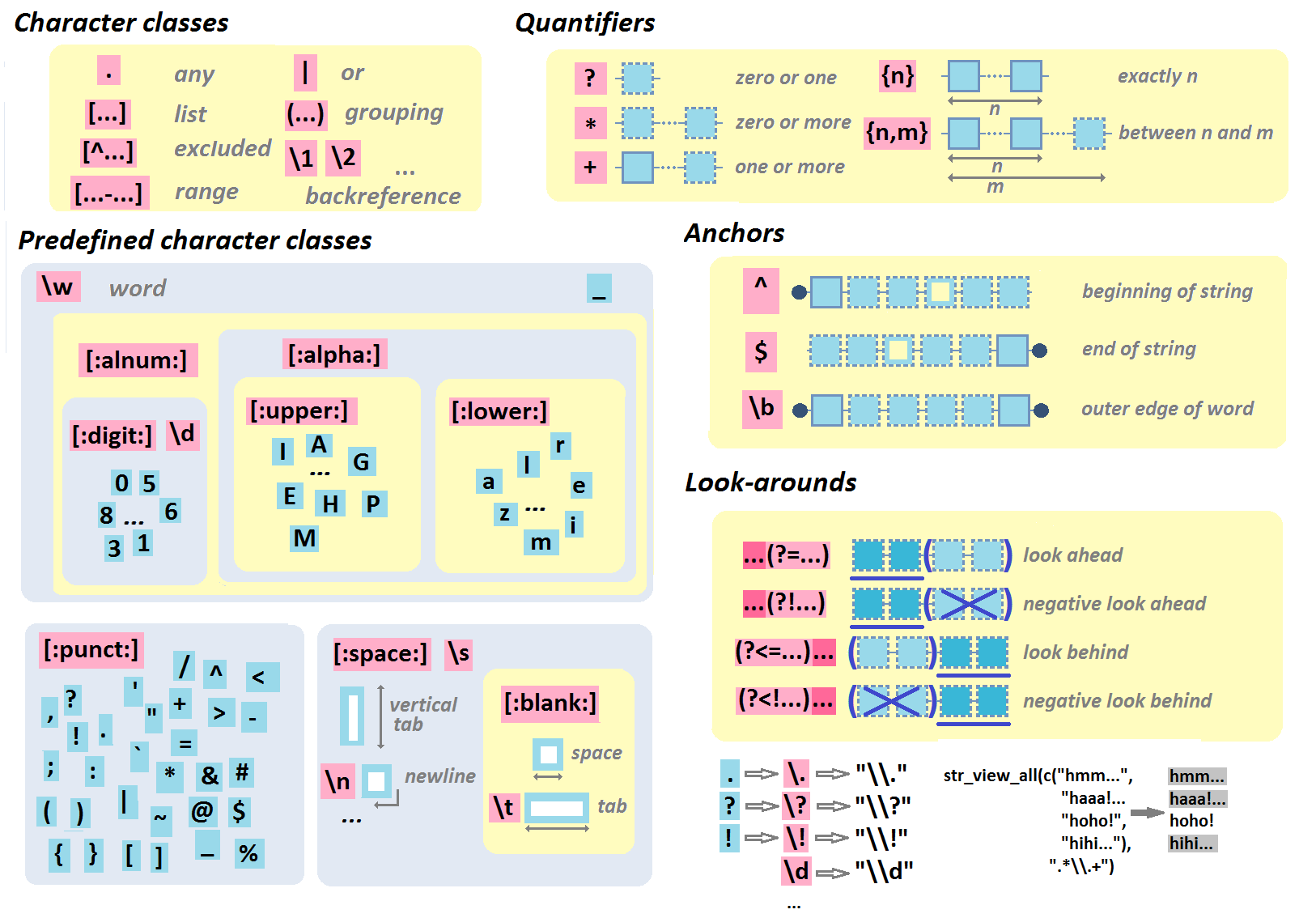
Regular Expression - Group (Capture|Substitution)
About
group are regexp expression that captures by default the match. You can then (extract|reference) the match content.
Look-around are also groups but implements an assertion and are not capturing the content
Example
The below regular expression has two groups
([^ ]) (.*)
where:
- the first group [^ ] will match all characters that not a space. Why ? It is:
- that contains only a space
- and the match is negated thanks to the ^ characters
- the second group is .* that will match all characters.
if you parse the following text:
Hello World
You will get:
- in the first group, \1, the text Hello
- and in the second group, \2, the text World
See more example here: Examples on how to replace a text in Notepad++ with regular expression
Syntax
Every group must begin with an open bracket and end with a close bracket.
(myRegexp0 ( myRegexp1) ( myRegexp2) )
| Construct | Definition |
|---|---|
| (?<name>X) | X, as a named-capturing group |
| non-capturing | |
| (?:X) | X, as a non-capturing group |
| (?>X) | X, as an independent, non-capturing group |
| Assertion (See Regexp - Look-around group (Assertion) - ( Lookahead | Lookbehind )) | |
| (?=X) | X, positive lookahead (via zero-width) |
| (?!X) | X, negative lookahead (via zero-width) |
| (?<=X) | X, positive lookbehind (via zero-width) |
| (?<!X) | X, negative lookbehind (via zero-width) |
| Flag | |
| (?idmsuxU-idmsuxU) | Nothing, but turns match flags i d m s u x U on - off |
| (?idmsux-idmsux:X) | X, as a non-capturing group with the given flags i d m s u x on - off |
Name
By default, the group is indexed by index (0,1,2,…) but you can give it a name with the following syntax
(?<name>X)
where X is the regular expression pattern that you want to capture
It's called a named-capturing group.
Index
Capturing groups are numbered by counting their opening parentheses from left to right.
In the expression ((A)(B(C))), for example, there are the following groups:
- 0 - Group zero always stands for the entire expression - ((A)(B(C)))
- 1 - ((A)(B(C)))
- 2 - (A)
- 3 - (B(C))
- 4 - (C)
Non-Capturing
Basic
A non capturing group will not be indexed.
In the expression (?:A)(B)(C), for example, there are the following groups:
- 0 - Group zero always stands for the entire expression - (?:A)(B)(C)
- 1 - (B)
- 2 - (C)
The group (?:A) was not captured.
Look-around
Regexp - Look-around group (Assertion) - ( Lookahead | Lookbehind )
Substitution
When you want to use the content of each captured group, you will generally use the following substitution construct:
- ${n} for the group index
- ${groupName} for the group name
When using group index, this construct must be used when:
- the number of group is greater than 9
- you want a number that follow the substitution
The dollar is also not always mandatory:
- $n for the group index
- $groupName for the group name
Their is also a shorthand notation for groups up to 9.
| Symbol | Definition |
|---|---|
| \0 | backreference to the entire expression |
| \1 | backreference to group 1 |
| \2 | backreference to group 2 |
| \n | backreference to group n |