Cryptography - Hash
About
A hash function is an encryption crypto algorithm that
- takes as data as input (possibly large and of variable-sized)
- and produces a short fixed-length integer value (generally printed as an hexadecimal string)
- that identify uniquely the input data with a very high probability.
In this function:
- the input data is called the message
- the output (digest) is called:
- the hash value
- the hash code,
- the hash sum,
- the hash key,
- or simply hash.
It's a one way function (you can't retrieve the input) but the output will change for a slight change in the input.
The integer is produced within a given range. A good hash function should generate integer uniformly on this range.
Example
With sha256:
Usage
Hash functions are used to:
- summarize an array of data in order to retrieve it faster
- distribute data or request
- speed up data retrieval (See hashmap where the hash is used as the key to distribute the data)
In database application, Hash functions are mostly used to speed up:
- index (hashmap)
- table lookup (Oracle Database - Hash joins)
- data comparison tasks
such as :
- finding items in a database,
- detecting duplicated or similar records in a large file,
- implementing Slowly Changing Dimensions type 2
- and so on.
Algo
Without secret
-
- SHA-3
- bcrypt
With Secret
Library
Property
Character Position
Position Independent: CRC16 and CRC32 (cyclical redundancy checksum, 16 bit and 32 bit). The hash of Foo or ooF will be the same. The position of the letter doesn't matter.
Cryptographic strength
Collision
An hash collision happens when two different inputs produce the same result. See Collisions of Hash or Identifier Generation
Distribution
In a distributed system or distributed data structure, you hash to distribute the request or the data.
- In distributed system, you don't want to request always the same server. If you hash by time for instance, you can have only one server that serves the most request (ie for the current time)
- In distributed data structure (ie hasmap), you don't want the data to go on the same place (ie in bucket)
Regular
Regular Hashing = Round Robin = Modular function
Assign M data keys to N servers assign each key to server = k mod N where:
- k is the key
- and N is the number of server
For instance:
- key 0 → server 0
- key 1 → server 1
- key 2 → server 2
- key 3 → server 0
- key 4 → server 1
- ….
If the number of servers increase from N to 2N, every existing key needs to be remapped, relocated.
Consistent
In consistent hashing, only a portion of keys need to be transferred to new storage space (a server) when more storage allocated. All data keys do not need to be rehashed like in regular hashing.
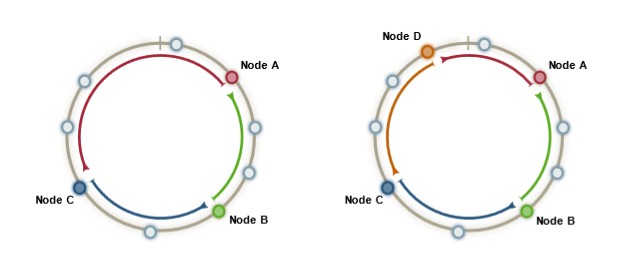
When the node D is added, only the data on the orange segment need to be reallocate from the Node A to the Node D.
Each server memorize the locations of other servers in the ring and can forward any incoming request.