
Database - (Software|Design Space|Category)
List
- http://greenplum.org/, Greenplum Massively parallel open source data warehouse Originally based on PostgreSQL
- Google Big Table (See also: https://accumulo.apache.org/)
- Drill A single query can join data from multiple datastores.
Datawarehouse
Design Space
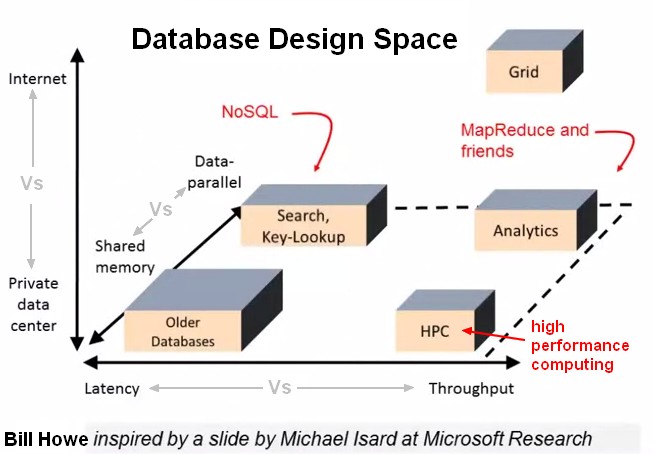
Db Design Space
to continue
| Db | Select | Insert/Update | Notes |
|---|---|---|---|
| Amazon Athena | Yes | No | Query data against S3 |
| Engine | (MapReduce Dependency|Batch Mode) | Description |
|---|---|---|
| Impala | No | Impala is well-suited to executing SQL queries for interactive exploratory analytics on large datasets. |
| Apache Hive | Yes | Hive and MapReduce are better tools for very long running, batch-oriented tasks such as ETL. |
Real Time
Interactive SQL support to data stored in Hadoop:
- Hadapt,
- or the Apache Drill project
They are based on Google’s ad-hoc query system called Dremel.
Batch
See Hive - Hive command line with Map Reduce