
Apache Drill
About
Drill is a SQL Engine aimed to be able to query data file stored in a file system structure.
At the core of Apache Drill is the 'Drillbit' service, which is responsible for accepting requests from the client, processing the queries, and returning results to the client.
Drill uses ZooKeeper to maintain cluster membership and health-check information.
Workpsace
https://drill.apache.org/docs/workspaces/
You can define one or more workspaces in a storage plugin configuration. The workspace defines the location of files in subdirectories of a local or distributed file system. Drill searches the workspace to locate data when you run a query. A hidden default workspace, dfs.default, points to the root of the file system.
Storage Plugin and configuration
A storage plugin is a software module for connecting Drill to data sources.
A storage plugin :
- optimizes execution of Drill queries,
- provides the location of the data,
- configures a workspace
- configure file formats for reading data.
Doc:
File System and Data Type
Local or Distributed (HDFS) with the following file types:
- Plain text files, including:
- Comma-separated values (CSV, type: text)
- Tab-separated values (TSV, type: text)
- Pipe-separated values (PSV, type: text)
- Structured data files:
- Avro (type: avro)
The extensions for these file types must match the configuration settings for your registered storage plugins. For example, PSV files may be defined with a .tbl extension, while CSV files are defined with a .csv extension.
Storage Supported: Data Sources and File Formats
Others Data Source:
- Hive (Data Type Mapping), Hive Plugin
- MapR-DB
alter session set `store.format`='parquet';
Storage Plugin Conf
Drill saves storage plugin configurations:
- in a temporary directory (embedded mode)
- or in ZooKeeper (distributed mode).
For example, on Mac OS X, Drill uses /tmp/drill/sys.storage_plugins to store storage plugin configurations. The temporary directory clears when you reboot. When you run drill in embedded mode, add the sys.store.provider.local.path option to the drill-override.conf file and the path for storing the plugin configurations.
drill.exec: {
cluster-id: "drillbits1",
zk.connect: "localhost:2181",
sys.store.provider.local.path="/mypath"
}
Schema / Connection
Schema in Drill are storage plugin.
The Drill installation registers the cp, dfs, hbase, hive, and mongo default storage plugin configurations.
Classpath (cp)
The cp schema points to JAR files in the Drill classpath, such as employee.json that you can query.
It's implemented by the cp (classpath) storage plugin.
Example:
SELECT * FROM cp.`employee.json` LIMIT 3;
File System (dfs)
dfs points to the root local file system (Relative seems to not work). You can configure this storage plugin to point to any distributed file system, such as a Hadoop or S3 file system.
Example:
SELECT * FROM dfs.`/opt/apache-drill-1.20.0/sample-data/region.parquet`
Others
- hbase: Provides a connection to HBase.
- hive: Integrates Drill with the Hive metadata abstraction of files, HBase, and libraries to read data and operate on SerDes and UDFs.
- mongo: Provides a connection to MongoDB data.
Client Connection
Drill supports two kinds of client connections:
- Direct Drillbit Connection
- ZooKeeper Quorum Connection
Clients can communicate to a specific Drillbit directly or go through a ZooKeeper quorum to discover the available Drillbits before submitting queries.
The format of the JDBC URL differs slightly, depending on the way you want to connect to the Drillbit:
- random
- local,
- or direct.
JDBC URL Drill bit
A drillbit must be first started.
An URL to directly connect to a Drillbit.
jdbc:drill:drillbit=Host[:Port];Property1=Value;Property2=Value;...
- default port: 31010
- Properties are case-sensitive. Do not duplicate properties in the connection URL.
http://maprdocs.mapr.com/51/Drill/Using-JDBC-Driver-App.html
With Dbeaver and a ssh tunnel
- URL: jdbc:drill:drillbit=localhost:31010
- SSH: User and password
- Advanced Setting: Local Port 31010, Remote Port 31010
JDBC URL Zk
This section covers using the URL for a random or local connection. If you want ZooKeeper to randomly choose a Drillbit in the cluster, or if you want to connect to the local Drillbit, the format of the driver URL is:
jdbc:drill:zk=<zk name>[:<port>][,<zk name2>[:<port>]...<directory>/<cluster ID>;[schema=<storage plugin>]
where
- jdbc is the connection type. Required.
- schema is the name of a storage plugin configuration to use as the default for queries. For example,schema=dfs or schema=hive. Optional.
- zk name specifies one or more ZooKeeper host names, or IP addresses. Use local instead of a host name or IP address to connect to the local Drillbit. Required.
- port is the ZooKeeper port number. Port 2181 is the default. On a MapR cluster, the default is 5181. Optional.
- directory is the Drill directory in ZooKeeper, which by default is /Drill. Optional.
- cluster ID is drillbits1 by default. If the default has changed, determine the cluster ID and use it. Optional.
Starting Drill
Embedded mode
Embedded mode is a quick way to try Drill without having to perform any configuration tasks. A ZooKeeper installation is not required. Installing Drill in embedded mode configures the local Drillbit service to start automatically when you launch the Drill shell.
Java URL that will start the embedded mode. A Jdbc call will the following URL will start a server and stop the main thread.
set JAVA_HOME=C:\Java\jdk1.7.0_79
sqlline.bat -u "jdbc:drill:zk=local"
You can then see the service in the web console:
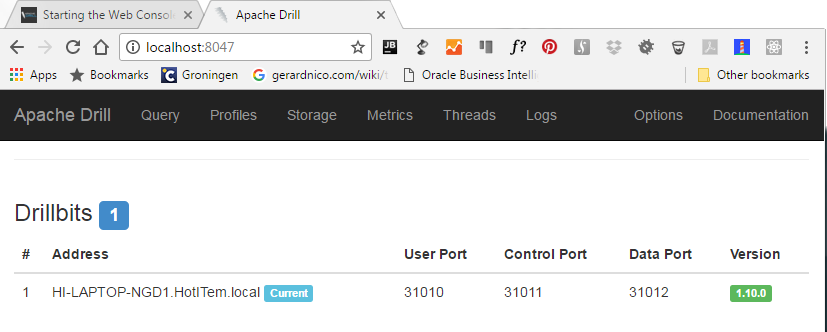
Dependency:
<!-- Running Drill in embedded mode using Drill's jdbc-all JDBC driver Jar file alone is not supported -->
<dependency>
<groupId>org.apache.drill.exec</groupId>
<artifactId>drill-jdbc</artifactId>
<version>1.10.0</version>
</dependency>
Distributed Mode
- Service script
drillbit.sh
Debug:
. ./drill-config.sh
./runbit debug
https://drill.apache.org/docs/starting-drill-in-distributed-mode/
CSV
SELECT * FROM dfs.`/tmp/csv_with_header.csv2`;
Config:
"csv": {
"type": "text",
"extensions": [
"csv2"
],
"skipFirstLine": false,
"extractHeader": true,
"delimiter": ","
},
- inline Configuration
select a, b from table(dfs.`path/to/data.csv`(type => 'text', fieldDelimiter => ',', extractHeader => true))
Log
- log.path
- log.query.path
Example with Java:
-Dlog.path="C:\apache-drill-1.1.0\log\sqlline.log" -Dlog.query.path="C:\apache-drill-1.1.0\log\sqlline_queries.log"
Example
SELECT * FROM dfs.`C:/apache-drill-1.1.0/sample-data/region.parquet`;
- PSV files (pipe-separated values): tbl extension
SELECT columns[1] as myAlias FROM dfs.`C:/myPath/ToPsvFiles.tbl`;
Metadata
You can query the following INFORMATION_SCHEMA tables:
- SCHEMATA
- CATALOGS
- TABLES
- COLUMNS
- VIEWS
SELECT CATALOG_NAME, SCHEMA_NAME as all_my_data_sources FROM INFORMATION_SCHEMA.SCHEMATA ORDER BY SCHEMA_NAME;
-- Shortcut
-- SHOW DATABASES; -- to show the database
-- show tables; -- to show the tables
+---------------+----------------------+
| CATALOG_NAME | all_my_data_sources |
+---------------+----------------------+
| DRILL | INFORMATION_SCHEMA |
| DRILL | cp.default |
| DRILL | dfs.default |
| DRILL | dfs.root |
| DRILL | dfs.tmp |
| DRILL | sys |
+---------------+----------------------+
System Table
The System Tables are in the sys schema
- List of tables
use sys;
show tables;
- System, session, and boot options:
select * from options where type='SYSTEM' limit 10;
- Boot, start parameters
select * from boot limit 10;
- Threads
select * from threads;
- Memory
select * from memory;
Version
select * from sys.version;
Querying in Directory
Assuming that bob.logdata is a workspace that points to the logs directory, which contains multiple subdirectories: 2012, 2013, and 2014.
The following query constrains files inside the subdirectory named 2013. The variable:
- dir0 refers to the first level down from logs,
- dir1 to the next level,
- and so on.
0: jdbc:drill:> USE bob.logdata;
+------------+-----------------------------------------+
| ok | summary |
+------------+-----------------------------------------+
| true | Default schema changed to 'bob.logdata' |
+------------+-----------------------------------------+
SELECT * FROM logs WHERE dir0='2013' LIMIT 10;
You can use query directory functions:
- to restrict a query to one of a number of subdirectories
- to prevent Drill from scanning all data in directories.
Reserved Word
reserved word must be enclosed by back ticks
`YEAR`
Interface/Client
- Drill shell
- Drill Web Console
- ODBC*
- JDBC
- C++ API
Configuration Options
Example for the admin security:
SELECT name, val FROM sys.`options` where name like 'security.admin%' ORDER BY name;
|name |val |
|--------------------------|---------------------------|
|security.admin.user_groups|%drill_process_user_groups%|
|security.admin.users |%drill_process_user% |
Support
File Not Found
file not found means that your file extensions in not recognize by an extension. For instance, PSV files (pipe-separated values) have a tbl extension.
Unexpected RuntimeException: java.lang.IndexOutOfBoundsException: Index: 0
Error during udf area creation [/C:/Users/gerard/drill/udf/registry] on file system https://issues.apache.org/jira/browse/DRILL-5101
mkdir %userprofile%\drill
mkdir %userprofile%\drill\udf
mkdir %userprofile%\drill\udf\registry
mkdir %userprofile%\drill\udf\tmp
mkdir %userprofile%\drill\udf\staging
takeown /R /F %userprofile%\drill