
About
The producer consumer model is used in order to execute a statement in parallel. The sets of PX servers work in pairs:
- one set is producing rows (producer)
- and one set is consuming the rows (consumer).
The rows have to be redistributed based on the join key to make sure that matching join keys from both tables are sent to the same PX servers process doing the join.
Articles Related
Example
In this example one set of PX servers reads and sends the data from table CUSTOMERS (producer) and another set receives the data (consumer) and joins it with table SALES.
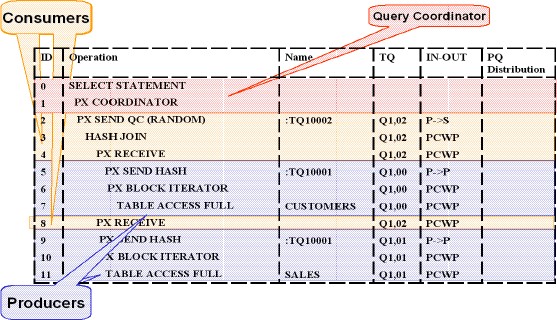
Operations (row-sources) that are processed by the same set of PX servers can be identified in an execution plan by looking in the TQ column.
As shown the above figure, the first slave set (Q1,00) is reading table CUSTOMERS in parallel and producing rows that are sent to slave set 2 (Q1,02) that consumes these records and joins then to record coming from the SALES table (Q1,01).
Whenever data is distributed from producers to consumers you will also see an entry of the form :TQxxxxx (Table Queue x) in the NAME column.
Number of PX server
This has a very important consequence for the number of PX server processes that are spawned for a given parallel operation: the producer/consumer model expects two sets of PX servers for a parallel operation, so the number of PX server processes is twice the requested degree of parallelism (DOP).
For example, if the parallel join runs with parallel degree of 4, then 8 PX server processes will be used for this statement, 4 producers and 4 consumers.
The only case when PX servers do not work in pairs is if the statement is so basic that only one set of PX servers can complete the entire statement in parallel. For example select count(*) from customers requires only one PX server set.