
About
Data redistribution is not unique to the Oracle Database. In fact, this is one of the most fundamental principles of parallel processing, being used by every product that provides parallel capabilities.
Parallel operations – except for the most basic ones – typically require data redistribution. Data redistribution is required in order to perform operations such as:
- parallel sorts,
- aggregations
- and joins.
At the block-granule level there is no knowledge about the actual data contained in an individual granule.
Data has to be redistributed as soon as a subsequent operation relies on the actual content.
Data redistribution takes place between individual PX servers either within a single machine, or, across multiple machines in a Real Application Clusters (RAC). Of course in the latter case interconnect communication is used for the data redistribution.
Articles Related
Architecture
The fundamental difference and advantage of Oracle's capabilities, however, is that parallel data access and therefore the necessary data redistribution are not constrained by any given hardware architecture or database setup.
Shared-nothing database systems also require data redistribution unless operations can take advantage of partition-wise joins. In shared-nothing systems, parallel operations that cannot benefit from a partition-wise join – such as a simple three-way table join on two different join keys - always make heavy use of interconnect communication.
Because the Oracle Database also enables parallel execution within the context of a node, parallel operations do not always have to use interconnect communication, thus avoiding a potential bottleneck at the interconnect.
Data Redistribution Methods
There are many data redistribution methods. The following 5 are the most common ones:
HASH
Hash redistribution is very common in parallel execution in order to achieve an equal distribution of work for individual PX servers based on a hash distribution. Hash (re)distribution is the basic parallel execution enabling mechanism for most data warehouse database system.
BROADCAST
Broadcast redistribution happens when one of the two result sets in a join operation is much smaller than the other result set. Instead of redistributing rows from both result sets the database sends the smaller result set to all PX servers in order to guarantee the individual servers are able to complete their join operation. The small result set may be produced in serial or in parallel.
RANGE
Range redistribution is generally used for parallel sort operations. Individual PX servers work on data ranges so that the QC does not have to do any sorting but only to present the individual parallel server results in the correct order.
KEY
Key redistribution ensures result sets for individual key values to be clumped together. This is an optimization that is primarily used for partial partition-wise joins to ensure only one side in the join has to be redistributed.
ROUND ROBIN
Round-robin data redistribution can be the final redistribution operation before sending data to the requesting process. It can also be used in an early stage of a query when no redistribution constraints are required.
RAC
As a variation on the data redistribution methods you may see a LOCAL suffix in a parallel execution plan on a Real Application Clusters (RAC) database. LOCAL redistribution is an optimization in RAC to minimize interconnect traffic for inter-node parallel queries. For example you may see a BROADCAST LOCAL redistribution in an execution plan indicating that the row set is produced on the local node and only sent to the PX servers on that node.
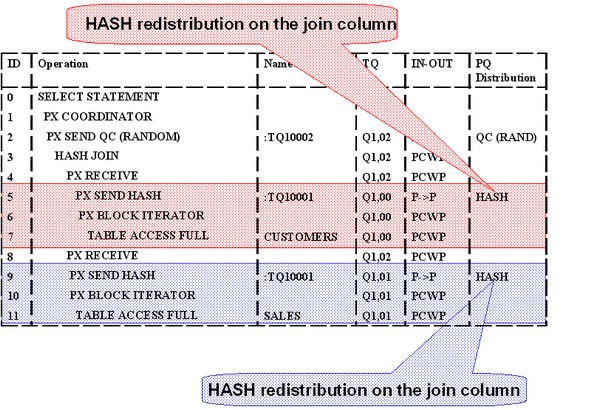
Example
simple example of table joins without any secondary data structures, such as indexes or materialized views.
Serial Join
In a serial join a single session reads both tables and performs the join. In this example we assume two large tables CUSTOMERS and SALES are involved in the join. The database uses full table scans to access both tables.
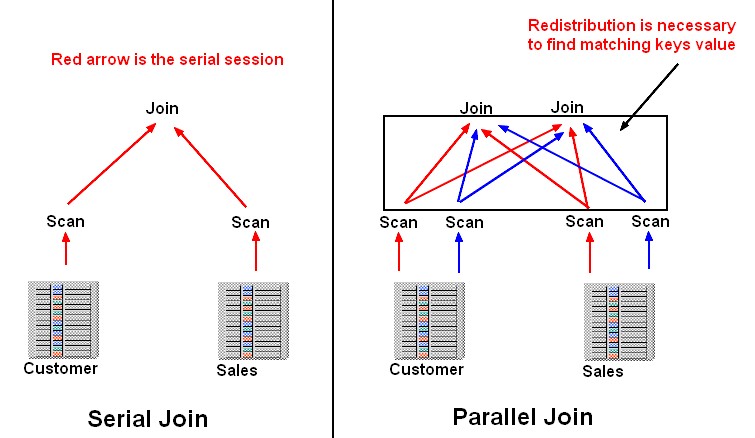
For a serial join the single serial session (red arrows) can perform the full join because all matching values from the CUSTOMERS table are read by one process.
Please note that the figures in this section represent logical diagrams to explain data redistribution. In an actual database environment data would typically be striped across multiple physical disks, accessible to any parallel server. This complexity has deliberately been left out from the images.
Parallel join
Processing the same simple join in parallel, a redistribution of rows will become necessary. PX servers scan parts of either table based on block ranges and in order to complete the join, rows have to be distributed between PX servers.
The figure depicts the data redistribution for a parallel join at a DOP 2, represented by the green and red arrow respectively. Both tables are read in parallel by both the red and green process (using block-range granules) and then each PX server has to redistribute its result set based on the join key to the subsequent parallel join operator.
In order to execute a statement in parallel efficiently sets of PX servers work in pairs: one set is producing rows (producer) and one set is consuming the rows (consumer). The rows have to be redistributed based on the join key to make sure that matching join keys from both tables are sent to the same PX server process doing the join. In this example one set of PX servers reads and sends the data from table CUSTOMERS (producer) and another set receives the data (consumer) and joins it with table SALES.