
Azure - Hive
About
Apache - Hive (HS|Hive Server) in Azure.
Hive comes with every cluster in Azure.
Articles Related
Protocol
Jdbc
# public name
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
# private
jdbc:hive2://fqdn:10001/default;transportMode=http;httpPath=/hive2
Dbeaver
Connection to a Spark Hive on a Spark cluster with Dbeaver.
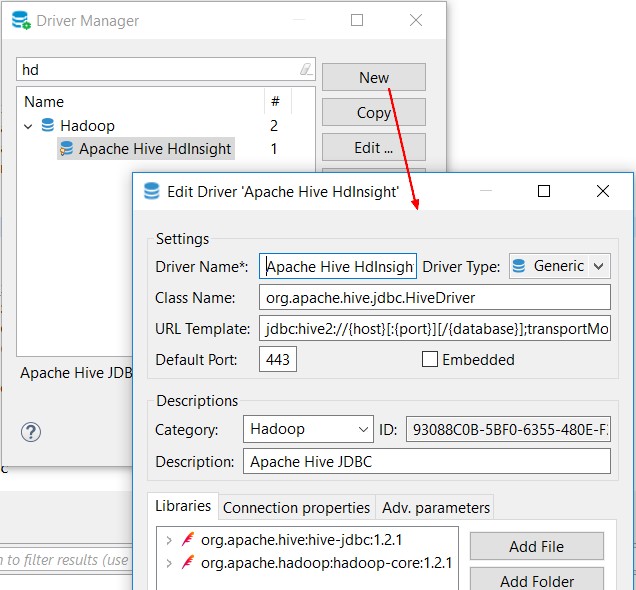
where:
- driver name = Apache Hive HdInsight
- class name = org.apache.hive.jdbc.HiveDriver
- URL template = jdbc:hive2://{host}[:{port}][/{database}];transportMode=http;ssl=true;httpPath=/hive2
- Default Port = 443
- Library: Add artifact:
- org.apache.hive - hive-jdbc - 1.2.1
- and org.apache.hadoop - hadoop-core - 1.2.1
Jar from dependency
From hdinsight-java-hive-jdbc - pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<!-- Hive version for HDInsight 3.5/3.6 -->
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<!-- Hive version for HDInsight 3.5/3.6 -->
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<!-- Hadoop version for HDInsight 3.5/3.6 -->
<version>2.7.3</version>
</dependency>
</dependencies>
Jar
All in one: hive-jdbc-1.2.1-standalone.jar
It must have the following jar files from the Hive Cluster as written in this documentation: Connect to Hive from JDBC
/usr/hdp/current/hadoop-client/hadoop-common.jar
/usr/hdp/current/hadoop-client/hadoop-auth.jar
/usr/hdp/current/hadoop-client/lib/log4j-*.jar
/usr/hdp/current/hadoop-client/lib/slf4j-*.jar
/usr/hdp/current/hive-client/lib/hive-*-1.2*.jar
/usr/hdp/current/hive-client/lib/httpclient-*.jar
/usr/hdp/current/hive-client/lib/httpcore-*.jar
/usr/hdp/current/hive-client/lib/libthrift-*.jar
/usr/hdp/current/hive-client/lib/libfb*.jar
/usr/hdp/current/hive-client/lib/commons-logging-*.jar
ODBC
Public Name
via public hostname of the cluster: see create hive odbc data source
Direct Local Connection to a head
Properties:
- The FQDN of either of the cluster headnodes: hn0-spark2.kuwf5gz2snuufbrn1smcqe5qyd.cx.internal.cloudapp.net
- Port: 10001
- Mechanism: User Name and Password
- User Name: The user name of the HTTP user you provisioned when you created the cluster. It defaults to admin.
- Password: Specify the password for the HTTP cluster user
- Thrift Transport: Choose HTTP