{kind=link}
About
Git is a content-addressable file system 1) used to track directory tree content (as defined by its creator Linux Torvald)
It's not a version control system but is used this way most of the time.
Setting up an environment: Git - Getting Started
How does the tracking happen?
The tracking happens with commits that creates a snapshot of the directory tree.
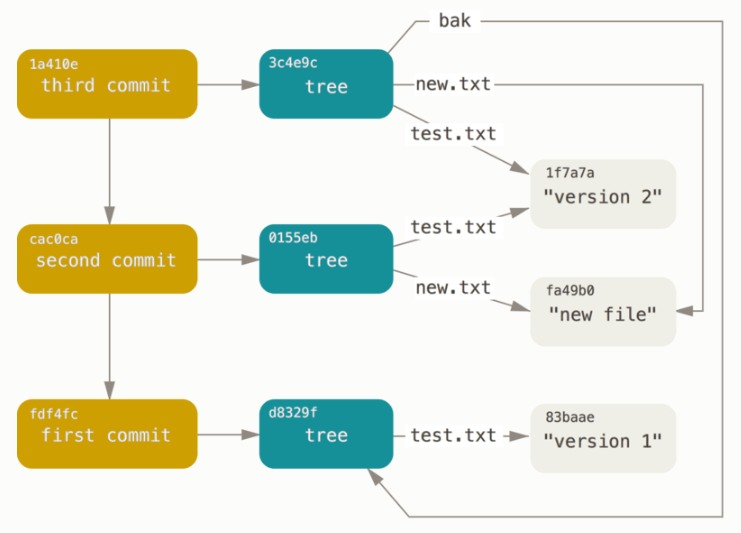
The commit identifiers are just a hash value (digest) (Meaning that no files are copied).
How is the data stored?
The core of Git is a database key-value data store. Every value (ie object) has a unique hash key.
The database stores:
- trees (for example: snapshots tree from a commit of a miniature filesystem.
The commit history being based on hash and not on file, it's cheap to create branch and supports non-linear development (thousands of parallel branches)
What does it mean that Git is distributed?
Instead of getting the current tip of the source code, you do a clone and get the entire repository. Every installation has a full backup of the whole history.
Every operation is then local. and operations are instantaneous.
File State
Git has three main file states:
| States | Description |
|---|---|
| Committed | The data is safely stored in the local database (The Git directory) |
| Modified | A modified file has not been committed to the local database yet |
| Staged | A modified file was marked in its current version to go into the next commit snapshot |
Directory
Three main sections of a Git project:
| Areas | File State | Description |
|---|---|---|
| Working directory | Modified | A single checkout of one version of the project (These files are pulled out of the Git directory and placed on disk to use or modify.) |
| Staging area (or index) | Modified and staged | Stores information and information that will go into the next commit |
| Git directory - Git - Head (Head Branch | Branch Head) / Last commit ?? | Commited | Store the metadata and object database for a project. (This is what is copied when a repository is cloned from another computer.) |
Workflow
Git will not allow you to push if someone has pushed since the last time you fetched, so a centralized model where all developers push to the same server works just fine.
Basic
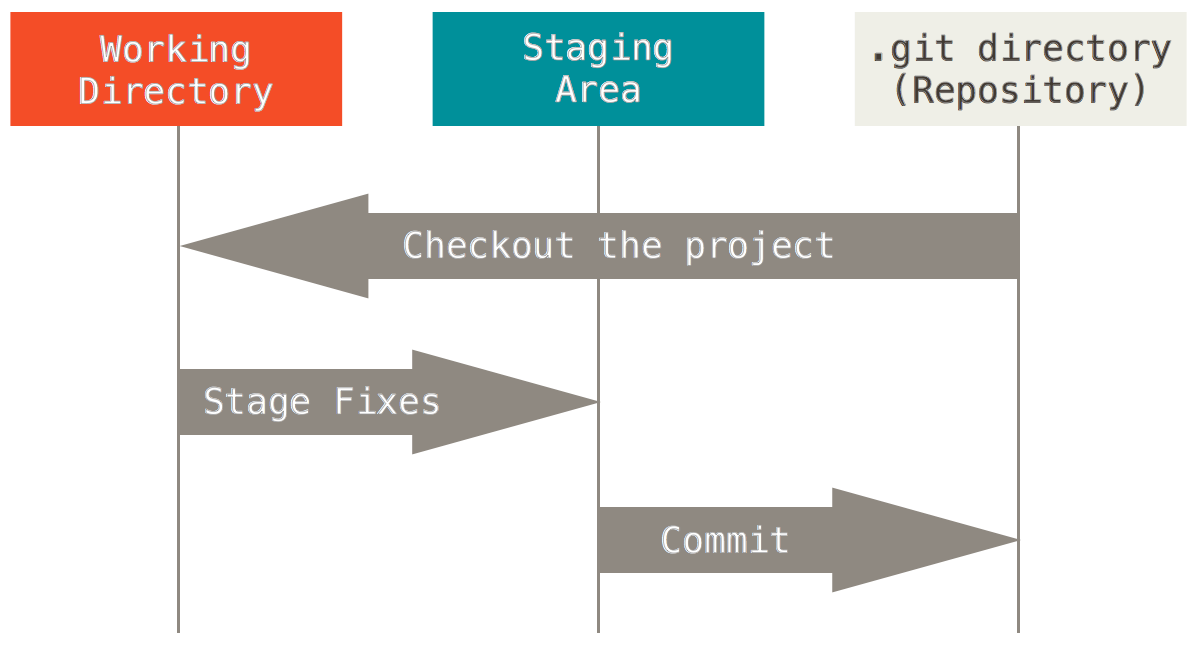
The basic Git workflow:
- Files are modified in the working directory.
- They are then staged through snapshots into the staging area.
- When a commit occurs, it takes the files in the staging area and stores that snapshot permanently to the Git directory.
| Workflow Order | Command | Description |
|---|---|---|
| 0 | git clone or git pull | Get a complete git repository from a remote and create a working directory Get the modifications (commits) from a remote |
| 1 | git add | Add the modifications to the staging area (Ready to be committed) |
| 2 | git add | Create a commit from the modifications (a permanently snapshot is created) |
| 3 | git push | Push the modifications (commits) to a remote |
Integration manager and lieutenants
Another common Git workflow involves an integration manager — a single person who commits to the 'blessed' repository. A number of developers then clone from that repository, push to their own independent repositories, and ask the integrator to pull in their changes.
For big project, the integration manager may got help of some people ('lieutenants') that are in charge of a specific subsystem of the project.
Action
Pages
Static website hosting